
{kind=link}
Ever puzzled in case your Mac mini M4 Professional might develop into an LLM powerhouse? The quick reply: not precisely — however it could actually run DeepSeek R1 fashions domestically with out counting on cloud-based AI servers. Right here’s tips on how to set it up utilizing Docker and Open WebUI for a seamless, ChatGPT-like expertise whereas holding your knowledge personal and below your management.
With the fitting configuration, your Mac mini can deal with fine-tuning, textual content era and retrieval duties with no need a devoted server. As an alternative of simply working AI in a fundamental terminal window, Docker and Open WebUI present a clean consumer interface for managing your fashions.
And for those who care about sovereign AI, this setup ensures all the pieces runs domestically — no API calls, no third-party logging and no cloud dependencies. Whether or not you’re testing b-parameter fashions, working benchmarks or tweaking logic for reinforcement studying, this step-by-step information will stroll you thru deploying DeepSeek R1 by yourself {hardware}.
TL;DR: Why that is thrilling
- No API limits: You personal it. No third-party restrictions.
- No cloud dependency: AI runs completely in your machine.
- Quick and optimized: Use GPU acceleration and tweak settings for peak efficiency.
- ChatGPT-like UI: Open WebUI turns your AI into a contemporary chatbot — no ugly terminal wanted.
- Expandable: Superb-tune fashions, run retrieval duties and customise as wanted.
Backside line: If you’d like actual AI in your laptop, that is the way you do it — sooner, smarter and totally in your management.
Mac mini and DeepSeek are a match made in Heaven
I used a Mac mini M4 Professional — which might run AI domestically for textual content, visuals and superior reasoning. Neglect cloud subscriptions, latency or sending knowledge to 3rd events.
With 64GB of unified reminiscence, a 20-core GPU and an M4 Professional chip, this machine can deal with some severe AI duties. Nevertheless, the terminal interface sucks. No spell verify, no chat historical past, no UI customization.
That’s the place Docker and Open WebUI are available. They flip your barebones terminal right into a ChatGPT-like expertise, full with saved chats, an intuitive interface and a number of fashions at your fingertips.
To be clear, we’re not utilizing the DeepSeek API. I’m working DeepSeek R1 fashions domestically utilizing llama.cpp (or Ollama) with out counting on any cloud API.
Dig deeper: What’s DeepSeek? A boon for entrepreneurs and a risk to Large Tech
Working DeepSeek domestically: What it’s essential to know
DeepSeek R1 features a vary of text-based fashions plus a 70B Imaginative and prescient variant for picture evaluation. Right here’s a rundown of its varied mannequin sizes.
| Mannequin | RAM Wanted | CPU Required | GPU Wanted? | Greatest Use Case |
| 1.5B ✅ | 8GB+ | Any trendy CPU | ❌ No | Fundamental writing, chat, fast responses |
| 8B ✅ | 16GB+ | 4+ Cores (Intel i5/Ryzen 5/M1) | ❌ No | Common reasoning, longer writing, coding |
| 14B ✅ | 32GB+ | 6+ Cores (Intel i7/Ryzen 7/M2) | ❌ No | Deeper reasoning, coding, analysis |
| 32B ⚠️ | 32-64GB+ | 8+ Cores (M3 Professional, Ryzen 9, i9) | ✅ Sure (Steel/CUDA really useful) | Advanced problem-solving, AI-assisted coding |
| 70B ⚠️ | 64GB+ | 12+ Cores (M4 Professional, Threadripper) | ✅ Sure (Excessive VRAM GPU really useful) | Heavy AI workflows, superior analysis |
| 70B Imaginative and prescient ⚠️ | 64GB+ | 12+ Cores (M4 Professional, Threadripper) | ✅ Sure (Steel/CUDA really useful) | Picture evaluation, AI-generated visuals |
| 1.671B ❌ | 512GB+ | 128+ cores (Server-only) | ✅ Should have a number of GPUs | Cloud solely — requires enterprise AI servers |
Prepared? Let’s set this up shortly, after which we’ll dive into optimizations so you may push CPU, GPU and reminiscence to the max.
The quickest solution to get DeepSeek working
In case you simply wish to get began proper now, that is your “quick and straightforward however ugly” setup to run in terminal.
1. Set up Ollama (the AI engine)
First, you want Ollama — the runtime that handles native AI fashions. Notice: It’s possible you’ll want to put in Python in case your laptop doesn’t have already got it.
Set up it:
/bin/bash -c "$(curl -fsSL https://ollama.com/obtain)"
Examine if it’s put in:
ollama --version
2. Obtain DeepSeek R1 (decide a mannequin measurement)
DeepSeek R1 is available in a number of sizes. The larger the mannequin, the smarter it will get and the slower it runs.
Decide a mannequin based mostly in your {hardware}:
ollama pull deepseek-r1:8b # Quick, light-weight
ollama pull deepseek-r1:14b # Balanced efficiency
ollama pull deepseek-r1:32b # Heavy processing
ollama pull deepseek-r1:70b # Max reasoning, slowest
3. Run DeepSeek R1 (fundamental mode)
To check the mannequin contained in the ugly terminal (for now):
ollama run deepseek-r1:8b
This works — but it surely’s like utilizing early ChatGPT API with no UI.
Now, let’s make it truly extra enjoyable to make use of each day.
Upgrading to a ChatGPT-like interface utilizing Docker and Open WebUI
Now that DeepSeek R1 is put in, let’s ditch the terminal expertise and transfer all the pieces right into a web-based chat UI with Docker + Open WebUI.
Set up Docker (required for Open WebUI)
Docker runs Open WebUI, which supplies you a contemporary chat interface as a substitute of utilizing the naked terminal.
Set up Docker:
Now, you may set up Open WebUI.
Set up Open WebUI (your native ChatGPT)
With Docker put in, we now run Open WebUI so you may chat with DeepSeek inside your browser.
Run this command in Terminal:
docker run -d --name open-webui -p 3000:3000 -v open-webui-data:/app/knowledge --pull=all the time ghcr.io/open-webui/open-webui:primary
This does three issues:
- Installs Open WebUI.
- Begins a server at
http://localhost:3000. - Runs it within the background.
Subsequent, open Chrome and go to:
http://localhost:3000
Your set up needs to be working! Now you could have a ChatGPT-style AI working domestically!
Join Open WebUI to DeepSeek R1 and also you now have a ChatGPT-style interface.
Native AI efficiency variables desk
Beneath is a one-stop “Efficiency Variables” Desk displaying all the important thing knobs you may flip (in Ollama or llama.cpp) to push your Mac mini — or any machine — to the max.
The {hardware} (CPU cores, GPU VRAM, whole RAM) is your mounted restrict, however these variables assist you dial in how that {hardware} is definitely used.
| Variable | Command / Env | What It Does | Typical Vary | Affect on Pace and Reminiscence | Commerce-Offs / Notes |
| CPU Threads | OLLAMA_THREADS=Nor --num-threads N (Ollama)--threads N (llama.cpp) |
Allocates what number of CPU threads (logical cores) are utilized in parallel. | 1 – 256
(Your actual max depends upon whole CPU cores; e.g., 14 cores → 28 threads on M4 Professional) |
Pace: Extra threads → sooner token processing (as much as diminishing returns).
Reminiscence: Barely elevated overhead. |
— In case you go too excessive, you may even see minimal features and even CPU scheduling overhead. — Begin round half or equal to your core depend (e.g., 8 or 16) and take a look at. |
| GPU Layers | --n-gpu-layers N (llama.cpp)
|
Specifies what number of mannequin layers to dump onto the GPU. | 0 – 999
(or as much as whole layers in your mannequin) |
Pace: Increased = extra GPU acceleration, large speedups if GPU has sufficient VRAM.
Reminiscence: Large fashions can exceed VRAM for those who push this too excessive. |
— For 70B or above, pushing 300+ layers to GPU might be enormous for pace, however you want sufficient VRAM (Steel or CUDA).
— On M4 Professional, take a look at round 100–400 GPU layers. |
| Batch Measurement | --batch-size N(llama.cpp) |
Variety of tokens processed per iteration (“mini-batch” measurement). | 1 – 512 (or extra) | Pace: Bigger batches → extra tokens processed directly, sooner throughput.
Reminiscence: Increased batch = extra RAM or VRAM used. |
— Ollama doesn’t at present help --batch-size totally.
— In case you get out-of-memory errors, decrease this. |
| Precedence | good -n -20 (Shell) |
Raises course of precedence so your AI duties get CPU time earlier than the rest. | -20 to 19 (most aggressive is -20) | Pace: AI course of steals CPU time from different apps.
Reminiscence: No direct affect, simply scheduling precedence. |
— In case you’re multitasking, your Mac may really feel laggy in different apps.
— Helpful in order for you each ounce of CPU for LLM duties. |
| Context Measurement | --context-size N (Ollama/llama.cpp) or -c N |
Units what number of tokens the mannequin can “bear in mind” in a single chat context. | 512 – 4096+ | Pace: Bigger context = extra tokens to course of every iteration.
Reminiscence: Increased context measurement makes use of extra VRAM/RAM. |
— Solely enhance for those who want longer context or larger prompts.
— Preserve at default (2,048 or 4,096) for regular utilization. |
| Temperature | --temp N (Ollama/llama.cpp) |
Controls how “inventive” or “random” the AI’s outputs are. | 0.0 – 2.0 (typical: 0.7–1.0) | Pace: No actual impact on efficiency, purely adjustments textual content model. | — 0.0 is deterministic, 1.0 is balanced, 2.0 can get wacky.
— This doesn’t push {hardware}, however price figuring out. |
| A number of Cases | and (Shell background processes) or separate Terminal classes |
Runs a number of copies of the mannequin directly to saturate CPU/GPU if a single mannequin doesn’t accomplish that. | 2+ separate runs | Pace: Mixed utilization can method 100% CPU/GPU if one occasion alone doesn’t saturate it.
Reminiscence: Double the utilization, can result in out-of-memory shortly. |
— Normally not really useful in order for you most pace on one chat.
— Nice in order for you 2+ parallel duties or mannequin comparisons. |
| Reminiscence Swap | System setting (macOS auto-manages) | Permits macOS to swap reminiscence to SSD whenever you run out of RAM. | Not user-configurable instantly | Pace: In case you exceed RAM, system swaps to disk — very gradual. | — Extra of a failsafe than a efficiency booster.
— In case you’re hitting swap closely, you want a smaller mannequin. |
| Concurrent Tokens | --prompt-batch-size N(varies) |
Some forks or variations of llama.cpp have a separate setting for concurrency in token era. | 1 – 128 (varies by fork) | Pace: Increased concurrency can generate tokens sooner in batch mode.
Reminiscence: Extra concurrency = extra RAM utilization. |
— Not all the time current in the primary branches.
— Nice for multi-client utilization or streaming. |
Fast tricks to truly push your laptop previous 20% utilization
Max threads
- Set
--threads or OLLAMA_THREADSto one thing close to your logical core depend (e.g., 28 if 14 bodily cores or attempt 64–128).
Excessive GPU layers
- In case you’re utilizing llama.cpp or Ollama with
--ngl, push it (e.g., 100–400 GPU layers for 70B). - Be careful for VRAM limits for those who set it too excessive.
Improve batch measurement
- In llama.cpp:
--batch-size 256or512can double or triple your throughput. - In case you see reminiscence errors or slowdowns, dial it again.
Use good precedence
good -n -20 ollama run deepseek-r1:70b… to hog CPU time.- However your Mac may stutter for those who do heavy duties within the background.
Don’t overextend context
- Preserve
--context-sizeat default except you want longer chat reminiscence. - Large context means extra reminiscence overhead.
Keep away from working a number of cases
- In case your objective is to push one chat to 100% utilization, don’t spin up a number of fashions.
- As an alternative, throw all sources at a single session with excessive threads and batch measurement.
Tips on how to monitor the utilization
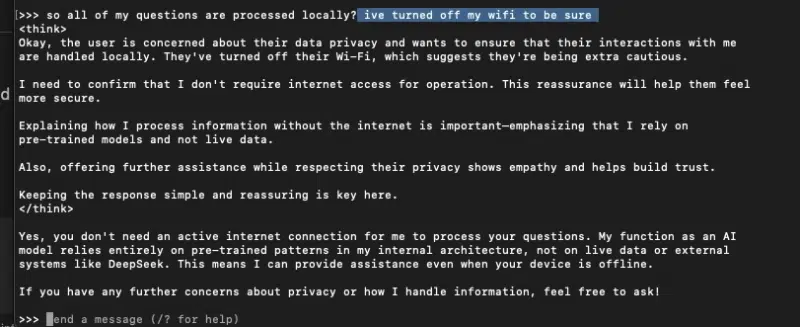
To get essentially the most out of your DeepSeek R1 setup, keep watch over your {hardware} utilization. Right here’s how.
Exercise monitor (macOS)
- Examine CPU (ought to spike) and GPU Historical past (ought to climb).
Terminal
htop→ CPU utilization throughout all cores.sudo powermetrics --samplers cpu_power,gpu_power -i 500→ Dwell GPU utilization.
In case your CPU continues to be idling under 20%, attempt incrementally growing threads, GPU layers and batch measurement. Finally, you’ll both see useful resource utilization climb or hit a reminiscence restrict.
Efficiency benchmarks: Actual occasions
To offer it a significant activity — like “write Tetris recreation in Python” — we recorded how lengthy every mannequin took to provide code:
- 1.8B: ~3 minutes 40 seconds
- 1.8B (second run, management): ~3 minutes 54 seconds
- 1.14B: ~6 minutes 53 seconds
- 32B: ~7 minutes 10 seconds
- 1.70B: ~13 minutes 81 seconds (approx. 13:48)
Curiously, smaller fashions run sooner, however 32B was barely slower than 14B. In the meantime, going all the way in which to 70B nearly doubles the time once more.
In case you want fast code or quick responses, the candy spot is often 14B or 32B — sufficient reasoning energy however not painfully gradual.
The mileage could differ relying in your Mac’s cooling, background duties and GPU acceleration settings.
All the time experiment with thread counts, batch sizes and reminiscence allocations to seek out the perfect trade-off in your system.
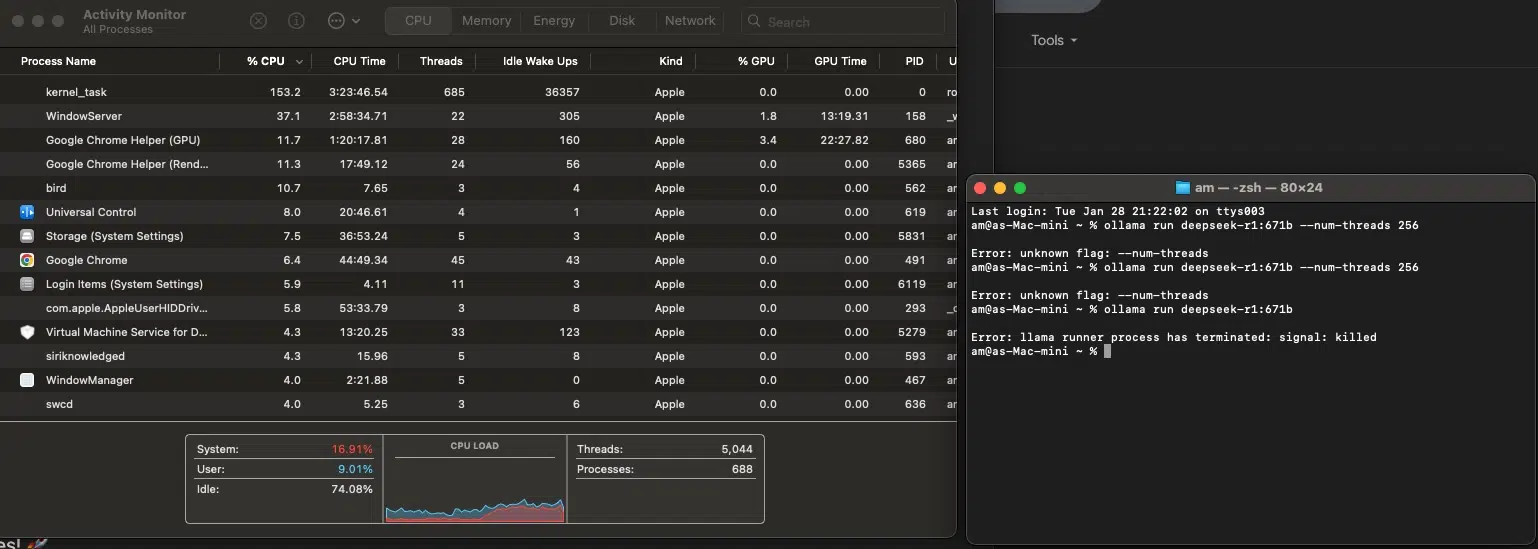
Why the 1.671B mannequin didn’t work (and received’t for most individuals)
Attempting to run DeepSeek R1: 1.671B on a Mac mini M4 Professional is like making an attempt to tow a semi-truck with a Tesla. It’s highly effective, however this job requires an 18-wheeler (i.e., a knowledge middle with racks of GPUs).
I knew it wouldn’t, however I needed to see what my Mac mini would do… and it simply canceled (crashed) the operation. Right here’s why it didn’t work:
It’s too large for My RAM
- The mannequin is 404GB, however my Mac mini solely has 64GB RAM.
- macOS killed it the second reminiscence ran out — as a result of it didn’t need the entire system to crash.
It’s constructed for cloud AI, not private computer systems
- This mannequin is supposed for servers with 1TB+ RAM and a number of GPUs.
- My M4 Professional’s 20-core GPU isn’t even near what’s wanted.
Swapping reminiscence received’t prevent
- Even when the SSD tries to behave like RAM, it’s too gradual for AI inference.
- The mannequin wants actual reminiscence, not a stopgap answer.
Large tech makes use of supercomputers for a purpose
- Firms like OpenAI or DeepSeek use 8+ enterprise GPUs to run fashions like this.
- Your laptop computer, Mac mini or gaming PC won’t ever run it domestically — it’s simply not designed for that.
What you must run as a substitute
If you’d like one thing that truly works on native {hardware}, attempt DeepSeek R1: 70B as a substitute:
ollama pull deepseek-r1:70b
ollama run deepseek-r1:70b
This mannequin is simply 40GB and truly suits inside a Mac mini’s RAM and GPU limits.
The lesson?
Know your limits. If you’d like 1.671B, you want cloud GPUs. If you’d like an actual native AI mannequin, follow 70B or smaller.
DeepSeek is now put in.
Dig deeper: Chris Penn talks DeepSeek and its large affect on entrepreneurs
Pushing native AI to the boundaries
Even when working domestically, DeepSeek R1 doesn’t totally escape the affect of its origins. Sure matters set off strict refusals.
Living proof:

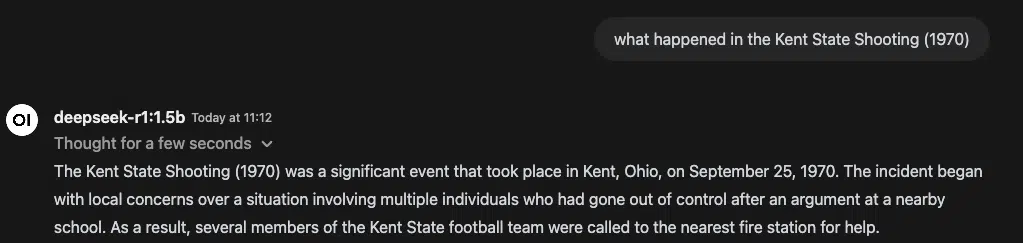
This isn’t only a curiosity — it’s a reminder that fashions skilled in several geopolitical environments include biases baked in.
It doesn’t matter for those who’re utilizing self-verification, chain-of-thought reasoning or retrieval-augmented era (RAG) — if the info is skewed, so is the output.
As AI builders, we must always all the time query responses, cross-check details and take into account mixing a number of fashions for a extra balanced method. Sovereign AI is simply helpful when it’s additionally correct.
Janus mannequin for visible era
Subsequent up, I built-in Janus Professional 7B for multimodal era — bringing photos into the combination.
Keep tuned for updates on benchmarking, API latency and {hardware} setup for working native AI-generated visuals.
Professionals and cons of working DeepSeek R1 and Janus domestically
Professionals: Why working AI domestically is superior
- No cloud, no api restrictions
- You personal it. No subscription, no fee limits, no third-party management.
- Works offline — your knowledge stays personal.
- Quicker response occasions (typically)
- No ready for cloud servers.
- Latency depends upon your {hardware}, not an exterior service.
- Extra management and customization
- Superb-tune fashions, modify parameters and experiment with completely different settings.
- Run a number of fashions directly (DeepSeek, Janus, Llama, and many others.).
- Cheaper in the long term
- No recurring charges for API entry.
- In case you already personal the {hardware}, it’s basically free to run.
- Helps superior options
- Chain-of-thought reasoning, self-verification and different advanced AI methods are nonetheless potential.
- RAG functions might be built-in for enhanced information recall.
Cons: What you’re lacking out on
- No web search (out of the field)
- Not like ChatGPT or Perplexity, DeepSeek R1 and Janus can’t fetch real-time net outcomes.
- You’d must combine a vector database or LangChain to attach it with exterior information.
- Restricted {hardware} = Slower efficiency
- Small fashions (1.5B, 8B) run high-quality, however something above 32B will get sluggish on most shopper {hardware}.
- Neglect about 1.671B except you could have a server rack and a number of GPUs.
- No built-in reminiscence or chat historical past
- Not like ChatGPT, your dialog resets each time (except you configure it).
- WebUI helps, however with out RAG or native embeddings, it’s forgetful.
- No pre-trained APIs for straightforward deployment
- In case you want Cloud APIs for manufacturing, you’re out of luck.
- Working DeepSeek R1 domestically ≠ ChatGPT API efficiency — it’s not plug-and-play.
- Some guardrails are nonetheless lively
- Regardless of working domestically, DeepSeek R1 nonetheless refuses to reply delicate matters.
- No jailbreak mode — you’d must fine-tune or modify system prompts manually.
- Setup is a ache (but it surely’s as soon as!)
- Putting in and optimizing Ollama, Docker, Open WebUI and Llama.cpp takes effort.
- It’s possible you’ll spend time tweaking CPU cores, RAM allocation and GPU acceleration to get the perfect efficiency.
What you’ve completed
- DeepSeek R1 is totally practical: This provides you a sovereign AI mannequin with RAG functions, optimized question processing and chain-of-thought reasoning.
- Open WebUI integration: No extra painful command strains. Your AI chat expertise feels seamless, with a fullscreen mode, chat menu and saved outputs.
- Efficiency tuning: We benchmarked completely different fashions, examined CPU cores, adjusted batch sizes and confirmed GPU acceleration for peak effectivity.
- Janus setup in progress: We bumped into some compatibility points (multi-modality), however we’re near unlocking its cutting-edge image-generation capabilities.
What’s subsequent?
- Refining your setup: Need higher self-verification in reasoning duties? Superb-tune mannequin parameters. Want sooner API latency? Experiment with vLLM optimizations.
- Increasing use instances: Combine LangChain to construct AI-powered functions or use a vector database for higher knowledge storage and retrieval.
- Cloud vs. native trade-offs: Some fashions, just like the 1.671B parameter beast, demand server-grade {hardware}. However for on-device reasoning, 70B or smaller is right.
Contributing authors are invited to create content material for MarTech and are chosen for his or her experience and contribution to the martech group. Our contributors work below the oversight of the editorial employees and contributions are checked for high quality and relevance to our readers. The opinions they specific are their very own.