

{kind=link}
The flexibility to generate 3D digital belongings from textual content prompts represents probably the most thrilling latest developments in AI and laptop graphics. Because the 3D digital asset market is projected to develop from $28.3 billion in 2024 to $51.8 billion by 2029, text-to-3D AI fashions are poised to play a serious function in revolutionizing content material creation throughout industries like gaming, movie, e-commerce, and extra. However how precisely do these AI programs work? On this article, we’ll take a deep dive into the technical particulars behind text-to-3D technology.

The Problem of 3D Era
Producing 3D belongings from textual content is a considerably extra complicated activity than 2D picture technology. Whereas 2D pictures are basically grids of pixels, 3D belongings require representing geometry, textures, supplies, and infrequently animations in three-dimensional house. This added dimensionality and complexity makes the technology activity far more difficult.
Some key challenges in text-to-3D technology embrace:
- Representing 3D geometry and construction
- Producing constant textures and supplies throughout the 3D floor
- Making certain bodily plausibility and coherence from a number of viewpoints
- Capturing advantageous particulars and world construction concurrently
- Producing belongings that may be simply rendered or 3D printed
To deal with these challenges, text-to-3D fashions leverage a number of key applied sciences and strategies.
Key Elements of Textual content-to-3D Techniques
Most state-of-the-art text-to-3D technology programs share a couple of core parts:
- Textual content encoding: Changing the enter textual content immediate right into a numerical illustration
- 3D illustration: A technique for representing 3D geometry and look
- Generative mannequin: The core AI mannequin for producing the 3D asset
- Rendering: Changing the 3D illustration to 2D pictures for visualization
Let’s discover every of those in additional element.
Textual content Encoding
Step one is to transform the enter textual content immediate right into a numerical illustration that the AI mannequin can work with. That is sometimes accomplished utilizing giant language fashions like BERT or GPT.
3D Illustration
There are a number of frequent methods to characterize 3D geometry in AI fashions:
- Voxel grids: 3D arrays of values representing occupancy or options
- Level clouds: Units of 3D factors
- Meshes: Vertices and faces defining a floor
- Implicit capabilities: Steady capabilities defining a floor (e.g. signed distance capabilities)
- Neural radiance fields (NeRFs): Neural networks representing density and colour in 3D house
Every has trade-offs by way of decision, reminiscence utilization, and ease of technology. Many latest fashions use implicit capabilities or NeRFs as they permit for high-quality outcomes with affordable computational necessities.
For instance, we will characterize a easy sphere as a signed distance perform:
import numpy as np
def sphere_sdf(x, y, z, radius=1.0):
return np.sqrt(x**2 + y**2 + z**2) - radius
# Consider SDF at a 3D level
level = [0.5, 0.5, 0.5]
distance = sphere_sdf(*level)
print(f"Distance to sphere floor: {distance}")
Generative Mannequin
The core of a text-to-3D system is the generative mannequin that produces the 3D illustration from the textual content embedding. Most state-of-the-art fashions use some variation of a diffusion mannequin, much like these utilized in 2D picture technology.
Diffusion fashions work by progressively including noise to knowledge, then studying to reverse this course of. For 3D technology, this course of occurs within the house of the chosen 3D illustration.
A simplified pseudocode for a diffusion mannequin coaching step may appear like:
def diffusion_training_step(mannequin, x_0, text_embedding): # Pattern a random timestep t = torch.randint(0, num_timesteps, (1,)) # Add noise to the enter noise = torch.randn_like(x_0) x_t = add_noise(x_0, noise, t) # Predict the noise predicted_noise = mannequin(x_t, t, text_embedding) # Compute loss loss = F.mse_loss(noise, predicted_noise) return loss # Coaching loop for batch in dataloader: x_0, textual content = batch text_embedding = encode_text(textual content) loss = diffusion_training_step(mannequin, x_0, text_embedding) loss.backward() optimizer.step()
Throughout technology, we begin from pure noise and iteratively denoise, conditioned on the textual content embedding.
Rendering
To visualise outcomes and compute losses throughout coaching, we have to render our 3D illustration to 2D pictures. That is sometimes accomplished utilizing differentiable rendering strategies that permit gradients to circulation again by means of the rendering course of.
For mesh-based representations, we would use a rasterization-based renderer:
import torch
import torch.nn.practical as F
import pytorch3d.renderer as pr
def render_mesh(vertices, faces, image_size=256):
# Create a renderer
renderer = pr.MeshRenderer(
rasterizer=pr.MeshRasterizer(),
shader=pr.SoftPhongShader()
)
# Arrange digicam
cameras = pr.FoVPerspectiveCameras()
# Render
pictures = renderer(vertices, faces, cameras=cameras)
return pictures
# Instance utilization
vertices = torch.rand(1, 100, 3) # Random vertices
faces = torch.randint(0, 100, (1, 200, 3)) # Random faces
rendered_images = render_mesh(vertices, faces)
For implicit representations like NeRFs, we sometimes use ray marching strategies to render views.
Placing it All Collectively: The Textual content-to-3D Pipeline
Now that we have coated the important thing parts, let’s stroll by means of how they arrive collectively in a typical text-to-3D technology pipeline:
- Textual content encoding: The enter immediate is encoded right into a dense vector illustration utilizing a language mannequin.
- Preliminary technology: A diffusion mannequin, conditioned on the textual content embedding, generates an preliminary 3D illustration (e.g. a NeRF or implicit perform).
- Multi-view consistency: The mannequin renders a number of views of the generated 3D asset and ensures consistency throughout viewpoints.
- Refinement: Further networks might refine geometry, add textures, or improve particulars.
- Remaining output: The 3D illustration is transformed to a desired format (e.g. textured mesh) to be used in downstream functions.
Here is a simplified instance of how this may look in code:
class TextTo3D(nn.Module):
def __init__(self):
tremendous().__init__()
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.diffusion_model = DiffusionModel()
self.refiner = RefinerNetwork()
self.renderer = DifferentiableRenderer()
def ahead(self, text_prompt):
# Encode textual content
text_embedding = self.text_encoder(text_prompt).last_hidden_state.imply(dim=1)
# Generate preliminary 3D illustration
initial_3d = self.diffusion_model(text_embedding)
# Render a number of views
views = self.renderer(initial_3d, num_views=4)
# Refine based mostly on multi-view consistency
refined_3d = self.refiner(initial_3d, views)
return refined_3d
# Utilization
mannequin = TextTo3D()
text_prompt = "A purple sports activities automotive"
generated_3d = mannequin(text_prompt)
Prime Textual content to 3d Asset Fashions Avaliable
3DGen – Meta
3DGen is designed to deal with the issue of producing 3D content material—reminiscent of characters, props, and scenes—from textual descriptions.
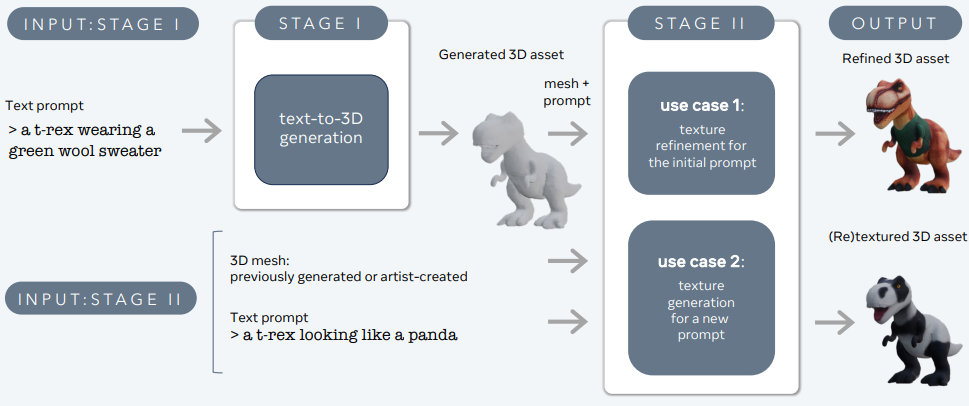
Giant Language and Textual content-to-3D Fashions – 3d-gen
3DGen helps physically-based rendering (PBR), important for real looking 3D asset relighting in real-world functions. It additionally allows generative retexturing of beforehand generated or artist-created 3D shapes utilizing new textual inputs. The pipeline integrates two core parts: Meta 3D AssetGen and Meta 3D TextureGen, which deal with text-to-3D and text-to-texture technology, respectively.
Meta 3D AssetGen
Meta 3D AssetGen (Siddiqui et al., 2024) is chargeable for the preliminary technology of 3D belongings from textual content prompts. This element produces a 3D mesh with textures and PBR materials maps in about 30 seconds.
Meta 3D TextureGen
Meta 3D TextureGen (Bensadoun et al., 2024) refines the textures generated by AssetGen. It can be used to generate new textures for present 3D meshes based mostly on further textual descriptions. This stage takes roughly 20 seconds.
Level-E (OpenAI)
Level-E, developed by OpenAI, is one other notable text-to-3D technology mannequin. Not like DreamFusion, which produces NeRF representations, Level-E generates 3D level clouds.
Key options of Level-E:
a) Two-stage pipeline: Level-E first generates an artificial 2D view utilizing a text-to-image diffusion mannequin, then makes use of this picture to situation a second diffusion mannequin that produces the 3D level cloud.
b) Effectivity: Level-E is designed to be computationally environment friendly, able to producing 3D level clouds in seconds on a single GPU.
c) Colour data: The mannequin can generate coloured level clouds, preserving each geometric and look data.
Limitations:
- Decrease constancy in comparison with mesh-based or NeRF-based approaches
- Level clouds require further processing for a lot of downstream functions
Shap-E (OpenAI):
Constructing upon Level-E, OpenAI launched Shap-E, which generates 3D meshes as an alternative of level clouds. This addresses a few of the limitations of Level-E whereas sustaining computational effectivity.
Key options of Shap-E:
a) Implicit illustration: Shap-E learns to generate implicit representations (signed distance capabilities) of 3D objects.
b) Mesh extraction: The mannequin makes use of a differentiable implementation of the marching cubes algorithm to transform the implicit illustration right into a polygonal mesh.
c) Texture technology: Shap-E may also generate textures for the 3D meshes, leading to extra visually interesting outputs.
Benefits:
- Quick technology instances (seconds to minutes)
- Direct mesh output appropriate for rendering and downstream functions
- Means to generate each geometry and texture
GET3D (NVIDIA):
GET3D, developed by NVIDIA researchers, is one other highly effective text-to-3D technology mannequin that focuses on producing high-quality textured 3D meshes.
Key options of GET3D:
a) Express floor illustration: Not like DreamFusion or Shap-E, GET3D instantly generates express floor representations (meshes) with out intermediate implicit representations.
b) Texture technology: The mannequin features a differentiable rendering approach to study and generate high-quality textures for the 3D meshes.
c) GAN-based structure: GET3D makes use of a generative adversarial community (GAN) strategy, which permits for quick technology as soon as the mannequin is skilled.
Benefits:
- Excessive-quality geometry and textures
- Quick inference instances
- Direct integration with 3D rendering engines
Limitations:
- Requires 3D coaching knowledge, which might be scarce for some object classes
Conclusion
Textual content-to-3D AI technology represents a basic shift in how we create and work together with 3D content material. By leveraging superior deep studying strategies, these fashions can produce complicated, high-quality 3D belongings from easy textual content descriptions. Because the expertise continues to evolve, we will anticipate to see more and more refined and succesful text-to-3D programs that can revolutionize industries from gaming and movie to product design and structure.