

Gemma 2 builds upon its predecessor, providing enhanced efficiency and effectivity, together with a collection of modern options that make it significantly interesting for each analysis and sensible functions. What units Gemma 2 aside is its capacity to ship efficiency akin to a lot bigger proprietary fashions, however in a bundle that is designed for broader accessibility and use on extra modest {hardware} setups.
As I delved into the technical specs and structure of Gemma 2, I discovered myself more and more impressed by the ingenuity of its design. The mannequin incorporates a number of superior methods, together with novel consideration mechanisms and modern approaches to coaching stability, which contribute to its exceptional capabilities.

Google Open Supply LLM Gemma
On this complete information, we’ll discover Gemma 2 in depth, inspecting its structure, key options, and sensible functions. Whether or not you are a seasoned AI practitioner or an enthusiastic newcomer to the sector, this text goals to offer useful insights into how Gemma 2 works and how one can leverage its energy in your personal initiatives.
What’s Gemma 2?
Gemma 2 is Google’s latest open-source giant language mannequin, designed to be light-weight but highly effective. It is constructed on the identical analysis and expertise used to create Google’s Gemini fashions, providing state-of-the-art efficiency in a extra accessible bundle. Gemma 2 is available in two sizes:
Gemma 2 9B: A 9 billion parameter mannequin
Gemma 2 27B: A bigger 27 billion parameter mannequin
Every dimension is on the market in two variants:
Base fashions: Pre-trained on an enormous corpus of textual content knowledge
Instruction-tuned (IT) fashions: High-quality-tuned for higher efficiency on particular duties
Entry the fashions in Google AI Studio: Google AI Studio – Gemma 2
Learn the paper right here: Gemma 2 Technical Report
Key Options and Enhancements
Gemma 2 introduces a number of important developments over its predecessor:
1. Elevated Coaching Information
The fashions have been skilled on considerably extra knowledge:
Gemma 2 27B: Skilled on 13 trillion tokens
Gemma 2 9B: Skilled on 8 trillion tokens
This expanded dataset, primarily consisting of net knowledge (largely English), code, and arithmetic, contributes to the fashions’ improved efficiency and flexibility.
2. Sliding Window Consideration
Gemma 2 implements a novel strategy to consideration mechanisms:
Each different layer makes use of a sliding window consideration with a neighborhood context of 4096 tokens
Alternating layers make use of full quadratic world consideration throughout your entire 8192 token context
This hybrid strategy goals to stability effectivity with the power to seize long-range dependencies within the enter.
3. Delicate-Capping
To enhance coaching stability and efficiency, Gemma 2 introduces a soft-capping mechanism:
def soft_cap(x, cap):
return cap * torch.tanh(x / cap)
# Utilized to consideration logits
attention_logits = soft_cap(attention_logits, cap=50.0)
# Utilized to ultimate layer logits
final_logits = soft_cap(final_logits, cap=30.0)
This system prevents logits from rising excessively giant with out arduous truncation, sustaining extra data whereas stabilizing the coaching course of.
- Gemma 2 9B: A 9 billion parameter mannequin
- Gemma 2 27B: A bigger 27 billion parameter mannequin
Every dimension is on the market in two variants:
- Base fashions: Pre-trained on an enormous corpus of textual content knowledge
- Instruction-tuned (IT) fashions: High-quality-tuned for higher efficiency on particular duties
4. Data Distillation
For the 9B mannequin, Gemma 2 employs information distillation methods:
- Pre-training: The 9B mannequin learns from a bigger trainer mannequin throughout preliminary coaching
- Publish-training: Each 9B and 27B fashions use on-policy distillation to refine their efficiency
This course of helps the smaller mannequin seize the capabilities of bigger fashions extra successfully.
5. Mannequin Merging
Gemma 2 makes use of a novel mannequin merging approach known as Warp, which mixes a number of fashions in three levels:
- Exponential Shifting Common (EMA) throughout reinforcement studying fine-tuning
- Spherical Linear intERPolation (SLERP) after fine-tuning a number of insurance policies
- Linear Interpolation In the direction of Initialization (LITI) as a ultimate step
This strategy goals to create a extra strong and succesful ultimate mannequin.
Efficiency Benchmarks
Gemma 2 demonstrates spectacular efficiency throughout numerous benchmarks:
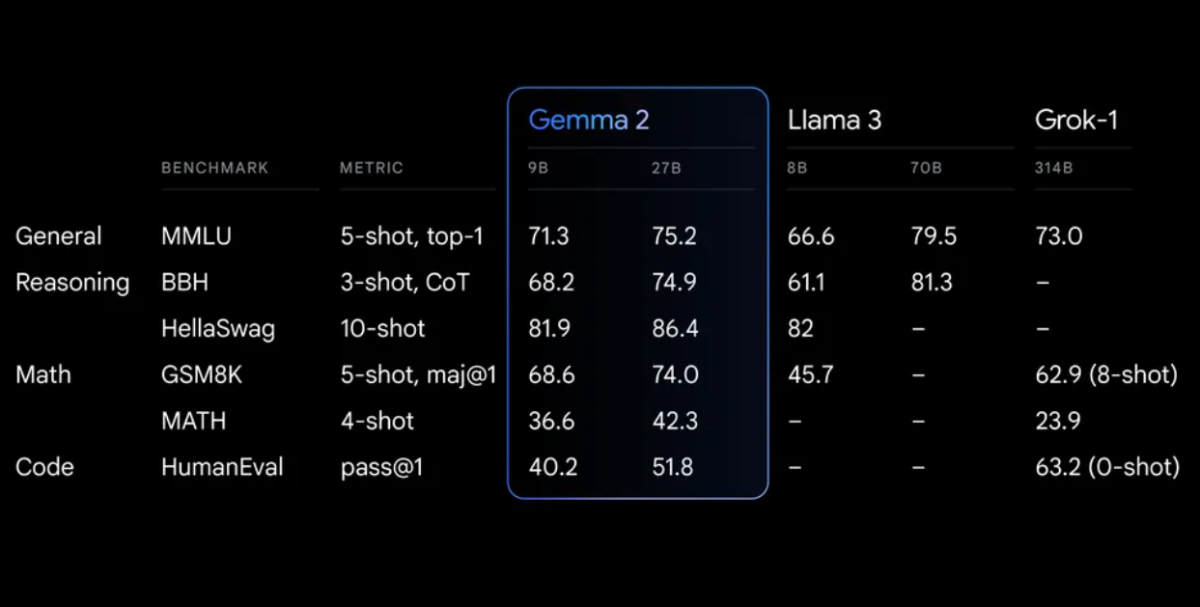
Gemma 2 on a redesigned structure, engineered for each distinctive efficiency and inference effectivity
Getting Began with Gemma 2
To start out utilizing Gemma 2 in your initiatives, you will have a number of choices:
1. Google AI Studio
For fast experimentation with out {hardware} necessities, you possibly can entry Gemma 2 by Google AI Studio.
2. Hugging Face Transformers
Gemma 2 is built-in with the favored Hugging Face Transformers library. Here is how you need to use it:
from transformers import AutoTokenizer, AutoModelForCausalLM # Load the mannequin and tokenizer model_name = "google/gemma-2-27b-it" # or "google/gemma-2-9b-it" for the smaller model tokenizer = AutoTokenizer.from_pretrained(model_name) mannequin = AutoModelForCausalLM.from_pretrained(model_name) # Put together enter immediate = "Clarify the idea of quantum entanglement in easy phrases." inputs = tokenizer(immediate, return_tensors="pt") # Generate textual content outputs = mannequin.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)3. TensorFlow/Keras
For TensorFlow customers, Gemma 2 is on the market by Keras:
import tensorflow as tf from keras_nlp.fashions import GemmaCausalLM # Load the mannequin mannequin = GemmaCausalLM.from_preset("gemma_2b_en") # Generate textual content immediate = "Clarify the idea of quantum entanglement in easy phrases." output = mannequin.generate(immediate, max_length=200) print(output)Superior Utilization: Constructing a Native RAG System with Gemma 2
One highly effective utility of Gemma 2 is in constructing a Retrieval Augmented Era (RAG) system. Let's create a easy, absolutely native RAG system utilizing Gemma 2 and Nomic embeddings.
Step 1: Organising the Atmosphere
First, guarantee you will have the mandatory libraries put in:
pip set up langchain ollama nomic chromadbStep 2: Indexing Paperwork
Create an indexer to course of your paperwork:
import os from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.document_loaders import DirectoryLoader from langchain.vectorstores import Chroma from langchain.embeddings import HuggingFaceEmbeddings class Indexer: def __init__(self, directory_path): self.directory_path = directory_path self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) self.embeddings = HuggingFaceEmbeddings(model_name="nomic-ai/nomic-embed-text-v1") def load_and_split_documents(self): loader = DirectoryLoader(self.directory_path, glob="**/*.txt") paperwork = loader.load() return self.text_splitter.split_documents(paperwork) def create_vector_store(self, paperwork): return Chroma.from_documents(paperwork, self.embeddings, persist_directory="./chroma_db") def index(self): paperwork = self.load_and_split_documents() vector_store = self.create_vector_store(paperwork) vector_store.persist() return vector_store # Utilization indexer = Indexer("path/to/your/paperwork") vector_store = indexer.index()Step 3: Organising the RAG System
Now, let's create the RAG system utilizing Gemma 2:
from langchain.llms import Ollama from langchain.chains import RetrievalQA from langchain.prompts import PromptTemplate class RAGSystem: def __init__(self, vector_store): self.vector_store = vector_store self.llm = Ollama(mannequin="gemma2:9b") self.retriever = self.vector_store.as_retriever(search_kwargs={"okay": 3}) self.template = """Use the next items of context to reply the query on the finish. If you do not know the reply, simply say that you do not know, do not attempt to make up a solution. {context} Query: {query} Reply: """ self.qa_prompt = PromptTemplate( template=self.template, input_variables=["context", "question"] ) self.qa_chain = RetrievalQA.from_chain_type( llm=self.llm, chain_type="stuff", retriever=self.retriever, return_source_documents=True, chain_type_kwargs={"immediate": self.qa_prompt} ) def question(self, query): return self.qa_chain({"question": query}) # Utilization rag_system = RAGSystem(vector_store) response = rag_system.question("What's the capital of France?") print(response["result"])This RAG system makes use of Gemma 2 by Ollama for the language mannequin, and Nomic embeddings for doc retrieval. It permits you to ask questions primarily based on the listed paperwork, offering solutions with context from the related sources.
High-quality-tuning Gemma 2
For particular duties or domains, you would possibly wish to fine-tune Gemma 2. Here is a fundamental instance utilizing the Hugging Face Transformers library:
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Coach from datasets import load_dataset # Load mannequin and tokenizer model_name = "google/gemma-2-9b-it" tokenizer = AutoTokenizer.from_pretrained(model_name) mannequin = AutoModelForCausalLM.from_pretrained(model_name) # Put together dataset dataset = load_dataset("your_dataset") def tokenize_function(examples): return tokenizer(examples["text"], padding="max_length", truncation=True) tokenized_datasets = dataset.map(tokenize_function, batched=True) # Arrange coaching arguments training_args = TrainingArguments( output_dir="./outcomes", num_train_epochs=3, per_device_train_batch_size=4, per_device_eval_batch_size=4, warmup_steps=500, weight_decay=0.01, logging_dir="./logs", ) # Initialize Coach coach = Coach( mannequin=mannequin, args=training_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["test"], ) # Begin fine-tuning coach.prepare() # Save the fine-tuned mannequin mannequin.save_pretrained("./fine_tuned_gemma2") tokenizer.save_pretrained("./fine_tuned_gemma2")Bear in mind to regulate the coaching parameters primarily based in your particular necessities and computational sources.
Moral Issues and Limitations
Whereas Gemma 2 affords spectacular capabilities, it is essential to pay attention to its limitations and moral concerns:
- Bias: Like all language fashions, Gemma 2 might mirror biases current in its coaching knowledge. At all times critically consider its outputs.
- Factual Accuracy: Whereas extremely succesful, Gemma 2 can typically generate incorrect or inconsistent data. Confirm necessary information from dependable sources.
- Context Size: Gemma 2 has a context size of 8192 tokens. For longer paperwork or conversations, you might have to implement methods to handle context successfully.
- Computational Assets: Particularly for the 27B mannequin, important computational sources could also be required for environment friendly inference and fine-tuning.
- Accountable Use: Adhere to Google's Accountable AI practices and guarantee your use of Gemma 2 aligns with moral AI rules.
Conclusion
Gemma 2 superior options like sliding window consideration, soft-capping, and novel mannequin merging methods make it a robust instrument for a variety of pure language processing duties.
By leveraging Gemma 2 in your initiatives, whether or not by easy inference, advanced RAG programs, or fine-tuned fashions for particular domains, you possibly can faucet into the ability of SOTA AI whereas sustaining management over your knowledge and processes.



{kind=link}