

{kind=link}
The world of search engine optimization has gotten more and more nuanced. Should you’re right here, that merely writing an article and shopping for hyperlinks to it hasn’t labored in a protracted whereas.
Once I’m working alone articles or with authors, I begin with outlines.
In spite of everything, it’s simpler to optimize items constructed to rank than to reverse engineer what you need later.
I’ve usually targeted lots of my consideration on understanding the content material and buildings of the top-ranking pages. Particularly, what questions they answered and what entities they contained.
I did lots of this manually. And it took lots of time.
Fortunately, with the rise of LLMs, a few APIs and a brand new scraper, we’re in a position to automate lots of this. This may cut back the period of time spent creating content material buildings that may rank. You possibly can spend that saved time including extra of the insights that solely you, as a human, can present.
This text will stroll you thru a script to create article outlines primarily based on:
- The key phrases you’re focusing on.
- The kind of article you wish to write.
- The highest entities that seem on the top-ranking web sites.
- The highest questions answered by the top-ranking websites.
- Summaries of the top-ranking websites.
And when you’re not fascinated about coding your self, I’ve even written a Google Colab you need to use. You solely want to join the APIs (straightforward) and click on some play buttons.
You’ll discover the Colab right here.
Earlier than we dive into the code, right here’s why I base my article outlines on these options.
Why use summaries, entities and prime questions for article outlines?
We may use a variety of options to encourage our outlines. I selected these three as a result of they kind the muse of what ought to be included in content material impressed by the highest 10. Right here’s why:
Summaries
Summaries show you how to distill what the top-ranking pages are doing properly, together with how they handle search intent.
Eager eyes will discover that I’ve targeted the summaries across the heading tags within the scripts. This ensures that once we educate the system to create an overview, it’ll take a look at the heading buildings of the top-ranking websites.
We’ll be utilizing a more moderen library known as Firecrawl, which places the content material in a markdown format. This enables us to base our understanding of the content material on extra superior structural components, together with headings. It is a huge leap ahead.
Entities
Entities are particular, well-defined ideas, equivalent to “synthetic intelligence,” “New York Metropolis” and even an thought like “belief.” Google acknowledges entities to higher perceive content material at a deeper stage, past simply key phrases.
For search engine optimization, this implies Google connects entities inside your content material to associated concepts, creating an internet of associations. Together with the highest entities related to your matter helps you align your article with what Google sees as contextually necessary and associated.
I rank the entities by their salience scores, which point out how necessary they’re to the web page’s content material.
Prime questions
Prime questions are one other key piece as a result of they characterize what actual customers wish to know.
My thought is that, by extension, questions Google needs answered. By answering these questions throughout the article, you’ll doubtless fulfill search intent extra totally.
Getting began
You possibly can run this script regionally in your machine utilizing an IDE (Built-in Growth Atmosphere).
The rest of this text is written for that atmosphere.
The good information? You possibly can have this all arrange and operating in your machine in just some minutes.
Should you’ve by no means used an IDE earlier than, you can begin by putting in Anaconda. It does many issues, however we solely wish to use Jupyter Pocket book for now.
Obtain and set up Anaconda right here, after which you’ll be able to merely launch “jupyter” to get going.
When you’ve carried out that, you’ll be able to bounce into the tutorial.
This route gives you a better general expertise. It can save you your API keys regionally and never should enter them every time. Plus, you’ll be able to edit the prompts and different variables extra simply.
Alternatively, you’ll be able to merely run the Colab. That is additionally a straightforward strategy to check whether or not it’s price establishing regionally.
Step 1: Getting your API keys
First, you’ll want to join the API keys you’ll want.
What’s an API?
APIs (utility programming interfaces) are primarily pipelines that allow completely different software program programs talk and share knowledge.
Consider them as a structured strategy to request particular knowledge or capabilities from a service (like Google or OpenAI) and get again precisely what you want, whether or not that’s analyzing entities on a web page, producing textual content or scraping content material.
The APIs we’ll want are:
- Customized search and Cloud Pure Language APIs (see beneath): That is to handle your {custom} search engine and extract entities from pages. It’s paid, however my invoice utilizing it quite a bit is only a couple {dollars} per thirty days.
- OpenAI: That is for content material evaluation and creation by way of GPT-4o. The API is low-cost (a greenback or two per thirty days below common use) and has a free trial.
- Firecrawl: That is for scraping webpages. As this stage, the free choice ought to work simply superb, however when you begin utilizing it a ton they do have cheap choices accessible.
- Weights & Biases (disclosure: I’m the pinnacle of search engine optimization at Weights & Biases): Enroll and acquire your API key. The free choice will do all the things we’d like.
Customized search and Google Cloud Pure Language APIs
I discovered getting these APIs arrange a bit non-intuitive, so I wished to save lots of you the ten minutes of figuring it out. Right here’s a step-by-step information to getting your self setup with the Google APIs:
To arrange your search engine, simply observe the fast directions at https://builders.google.com/custom-search/docs/tutorial/creatingcse.
The settings I take advantage of are:
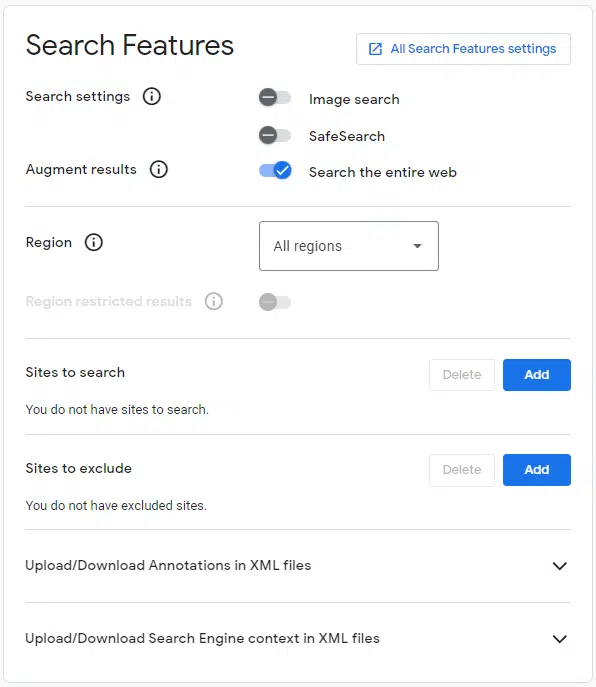
Google API key
The API key offers you entry to the search engine. Once more, it’s straightforward to arrange, and you are able to do so at https://assist.google.com/googleapi/reply/6158862?hl=en.
While you’re within the console, you’ll merely click on to Allow APIs and providers:
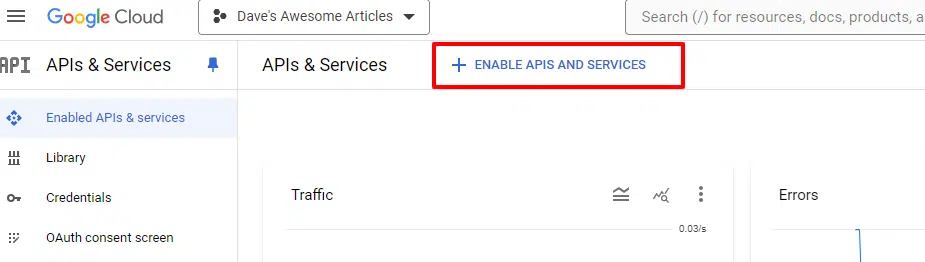
And also you’ll wish to allow the Customized Search API and Cloud Pure Language API.
You’ll additionally must arrange your credentials:
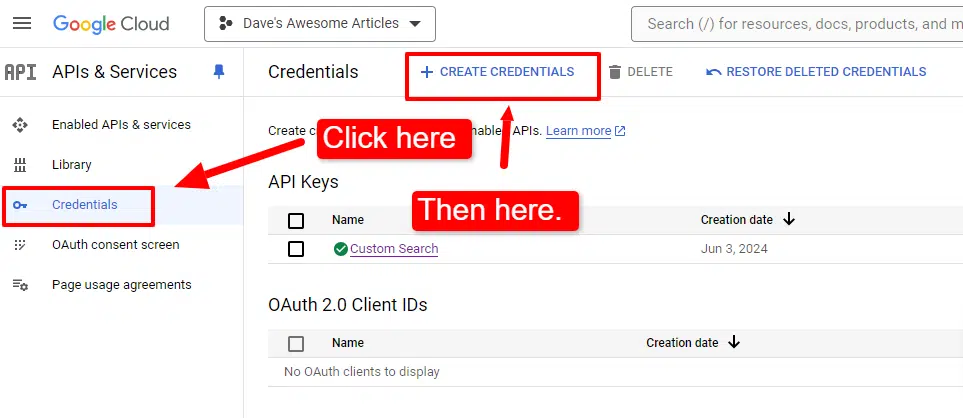
Then, choose API key from the drop-down:
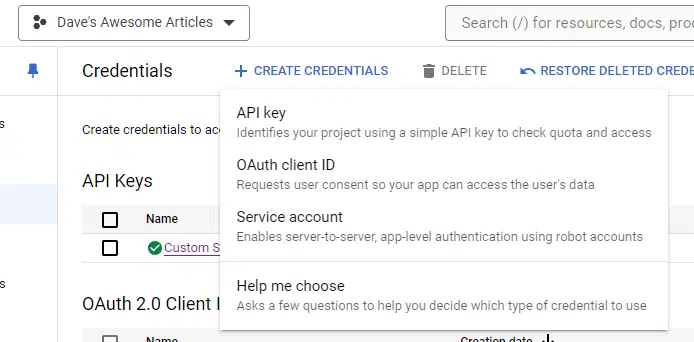
Copy the important thing to a Notepad file. It can save you it there, however we’ll want it in a second, so I usually paste mine in an unsaved doc.
For good measure, I like to recommend clicking on the API Key you simply created. It can have an orange triangle beside it, noting that it’s unrestricted.
You possibly can click on it, set the API to restricted and provides it entry to only the Customized Search API to assist safeguard towards misuse.
Google service account
When you’re on this display, you’ll be able to arrange the service account.
Once more, you’ll click on on Create credentials, however as a substitute of API key, you’ll click on Service account.
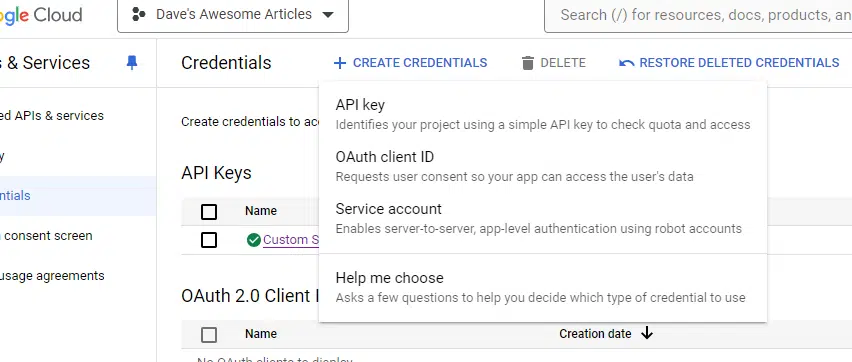
You’ll simply want to call your undertaking and choose the function.
As I’m the one one with entry to my tasks and machine, I simply set it as proprietor. You could wish to select in any other case. You’ll find out extra concerning the roles right here.
When you’ve created the service account, it is advisable create a key for it. Should you’re not routinely taken to take action, merely click on on the service account you simply created:
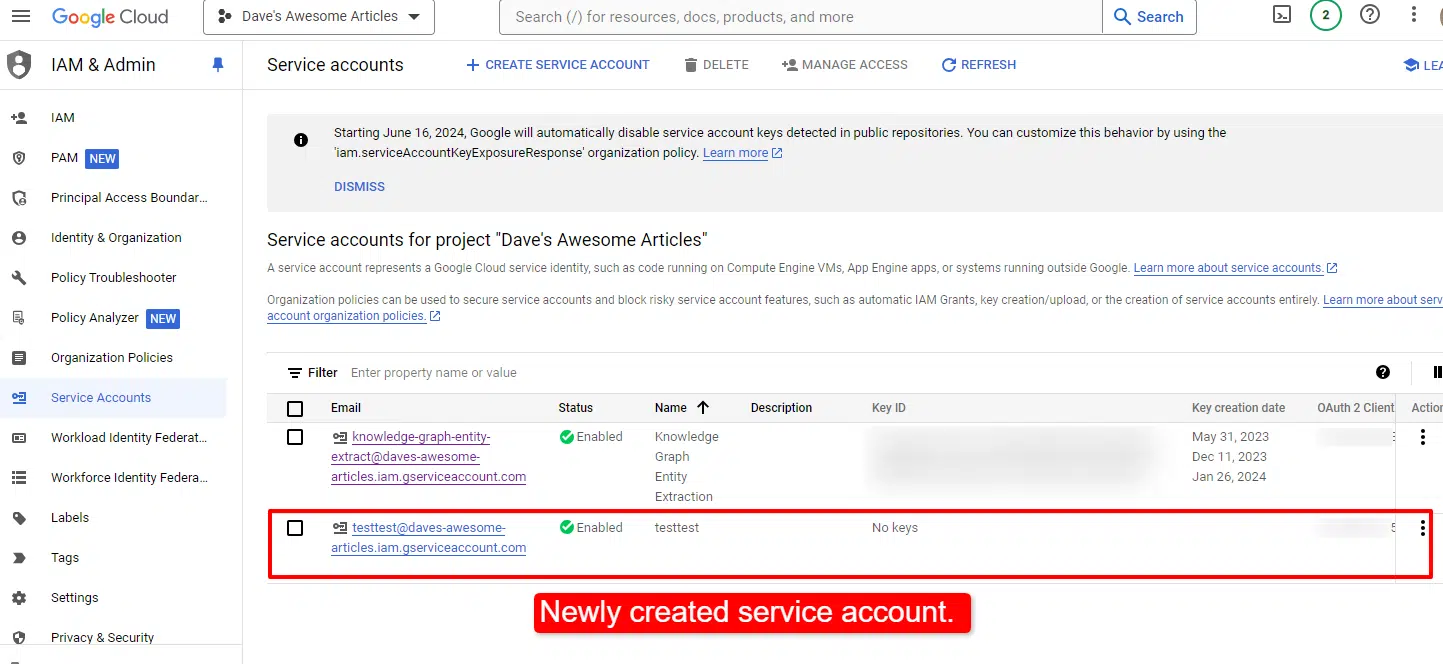
Click on Keys within the prime tabs after which Create new key.
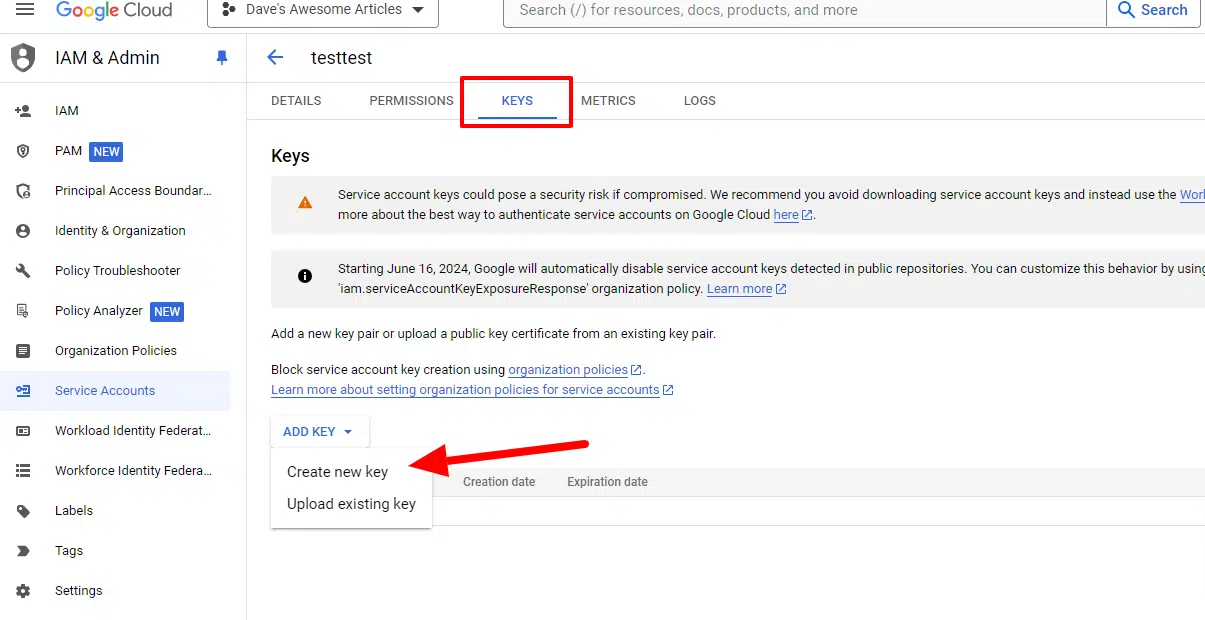
Select JSON.
The important thing will routinely obtain to your machine. Reserve it to a location the place it will probably keep and duplicate the trail to it. You’ll want that path and the filename shortly.
We’re able to get going! Open Jupyter Pocket book and add the code blocks. I like so as to add brief descriptions of what the blocks do for my future reference, however that’s as much as you.
Step 2: Defining the article you need an overview for
After you may have launched your Jupyter Pocket book (or most popular IDE) by opening the Anaconda immediate:

And coming into “jupyter pocket book”:
You’ll create a brand new Python 3 pocket book: File > New > Pocket book
And begin copying and pasting the code beneath into the cells:
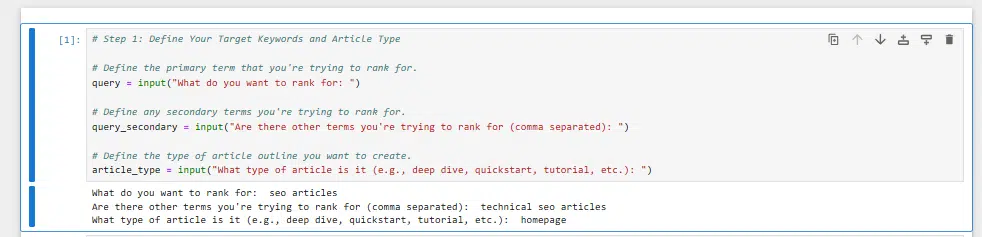
Within the first cell, we’ll enter:
# Step 1: Outline your goal key phrases and article kind
# Outline the first time period that you just're making an attempt to rank for.
question = enter("What do you wish to rank for: ")
# Outline any secondary phrases you are making an attempt to rank for.
query_secondary = enter("Are there different phrases you are making an attempt to rank for (comma separated): ")
# Outline the kind of article define you wish to create.
article_type = enter("What kind of article is it (e.g., deep dive, quickstart, tutorial, and so forth.): ")While you click on this cell, it’ll ask you the three questions above, which can be used additional beneath.
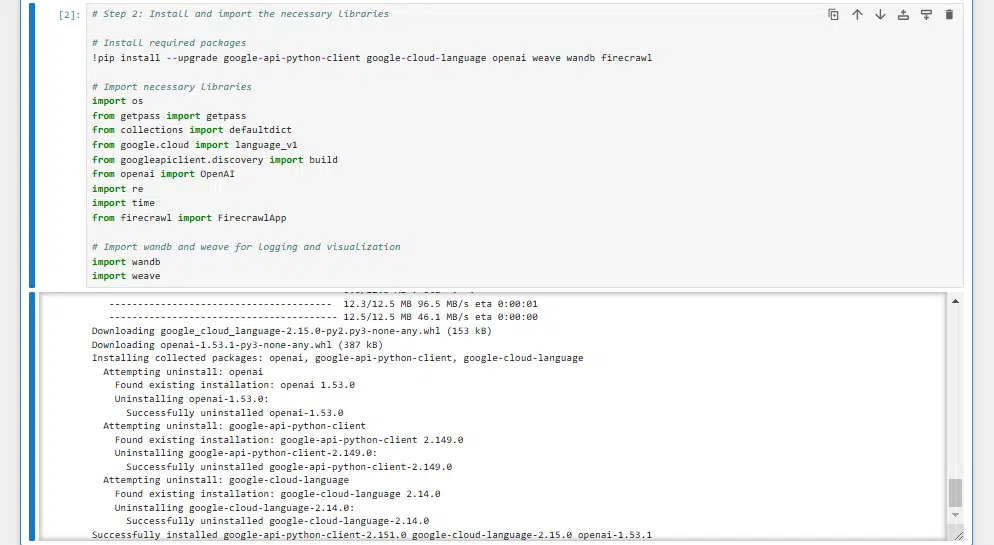
Step 3: Putting in the libraries you’ll want
The following step is to put in all of the libraries we’ll want. They’re:
- google.cloud.language_v1: That is a part of the Google Cloud NLP library, used for analyzing entities.
- googleapiclient.discovery.construct: We’re utilizing this one for our {custom} search engine.
- openai: Not surprisingly, we’re utilizing this one to work with the OpenAI API and use GPT-4o.
- firecrawl: We’re utilizing this one to scrape the highest webpages.
- wandb and weave: We’re utilizing these two libraries to log our prompts and different inputs for analysis.
- Some supporting libraries, like os, time and getpass, that merely facilitate performance.
You’ll set up these with the next code:
# Step 2: Set up and import the mandatory libraries
# Set up required packages
!pip set up --upgrade google-api-python-client google-cloud-language openai weave wandb firecrawl
# Import crucial libraries
import os
from getpass import getpass
from collections import defaultdict
from google.cloud import language_v1
from googleapiclient.discovery import construct
from openai import OpenAI
import re
import time
from firecrawl import FirecrawlApp
# Import wandb and weave for logging and visualization
import wandb
import weaveThis would possibly take a minute or two to run and can seem like:
Get the e-newsletter search entrepreneurs depend on.
Step 4: Including our APIs
This part differs from the Colab, the place you enter your API keys one after the other to keep away from leaving them in a public location.
In case you are working by yourself safe machine, it’s possible you’ll wish to add your API keys immediately into the script.
Alternatively, you need to use the code from the Colab for this block and have the script ask you to your API keys every time.
The code for this step is:
# Google API Key
google_api = 'YOUR_GOOGLE_API_KEY'
# Google Software Credentials (JSON file path)
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'C:/Customers/PATH_TO_YOUR_APPLICATION_CREDENTIALS/FILE.JSON'
# Google Customized Search Engine ID
google_search_id = 'SEARCH_ENGINE_ID'
# Firecrawl API Key
firecrawl_api_key = 'FIRECRAWL_API_KEY'
app = FirecrawlApp(api_key=firecrawl_api_key)
# Initialize Weights & Biases
wandb_api_key = 'WEIGHTS_AND_BIASES_API_KEY'
wandb.login(key=wandb_api_key)
# OpenAI API Key
openai_api_key = 'OPENAI_API_KEY'
os.environ["OPENAI_API_KEY"] = openai_api_keyKeep in mind above the place I famous you’d want to repeat the trail to the appliance file and in addition the filename itself. That’s what you place within the block:
C:/Customers/PATH_TO_YOUR_APPLICATION_CREDENTIALS/FILE.JSONFor instance, that line in my script seems to be like:

We’ve now set the stage. Let’s get into the meat of the script.
Step 5: Defining the capabilities
The following step is to outline the capabilities we’ll must make this all work.
The capabilities we’re defining are:
google_search: This operate makes use of Google’s Customized Search API to tug the highest 10 outcomes for the first time period we supplied in the first step.fetch_content_with_firecrawl: This one’s our scraper, fetching content material from the highest 10 utilizing Firecrawl. If a web page blocks entry, it’ll let and transfer on.extract_headings_from_markdown: Parses markdown content material and extracts the headings from the scraped content material.generate_summary: This operate leverages GPT-4o to create a concise abstract of every of the highest pages primarily based partly on the headings.extract_questions: This one pulls out important questions from the top-ranking pages utilizing GPT-4o.top_questions: This operate types by all of the extracted questions to seek out probably the most related and helpful ones throughout all of the top-ranking pages.analyze_entities: This one makes use of Google Cloud NLP to research and extract entities (the “who,” “what,” and “the place” of the content material). This helps us perceive what ideas are central to the textual content, so we will be sure these core components are woven into the article define.
The code for that is:
# Step 4: Outline capabilities
# Setup Google Search API
def google_search(search_term, api_key, cse_id, **kwargs):
service = construct("customsearch", "v1", developerKey=api_key)
res = service.cse().record(q=search_term, cx=cse_id, **kwargs).execute()
return res['items']
# Operate to extract content material from a webpage utilizing Firecrawl
def fetch_content_with_firecrawl(url):
strive:
scrape_result = app.scrape_url(url, params={'codecs': ['markdown']})
if '403 Forbidden' in scrape_result.get('standing', ''):
print(f"Entry to {url} was denied with a 403 Forbidden error.")
return None
page_text = scrape_result.get('markdown', '')
if not page_text:
print(f"No content material accessible for {url}")
return None
return page_text
besides Exception as e:
print(f"Error fetching content material from {url}: {str(e)}")
return None
# Operate to extract headings from markdown textual content
def extract_headings_from_markdown(markdown_text):
"""Extract headings from markdown textual content primarily based on markdown syntax."""
headings = []
for line in markdown_text.cut up('n'):
line = line.strip()
if line.startswith('#'):
# Take away main '#' characters and any further whitespace
heading = line.lstrip('#').strip()
if heading:
headings.append(heading)
return headings
# Operate to generate a abstract of the textual content utilizing OpenAI GPT-4o
def generate_summary(textual content, headings):
"""Generate a GPT-4o abstract of the textual content utilizing the headings."""
# Put together the immediate
headings_text="n".be part of(f"- {heading}" for heading in headings)
immediate = (f"Summarize the next article, specializing in these headings:n{headings_text}nn"
f"The abstract ought to be concise (max 500 tokens) and seize the important thing factors.")
strive:
response = shopper.chat.completions.create(
messages=[
{"role": "system", "content": "You are an expert summarizer."},
{"role": "user", "content": prompt + "nn" + text}
],
mannequin="gpt-4o",
max_tokens=500,
temperature=0.2,
n=1
)
abstract = response.selections[0].message.content material.strip()
return abstract
besides Exception as e:
print(f"Error producing abstract: {e}")
return "Abstract not accessible."
# Operate to extract questions from the textual content utilizing OpenAI GPT-4o
def extract_questions(textual content):
"""Extract questions from the textual content utilizing GPT-4o."""
immediate = (f"Extract the highest 5 most necessary questions from the next textual content associated to the question '{question}'. "
f"Checklist them as bullet factors.nn{textual content}")
strive:
response = shopper.chat.completions.create(
messages=[
{"role": "system", "content": "You are a helpful assistant who extracts key questions from texts."},
{"role": "user", "content": prompt}
],
mannequin="gpt-4o",
max_tokens=1000,
temperature=0.1,
n=1
)
questions_text = response.selections[0].message.content material.strip()
# Cut up the response into particular person questions primarily based on bullet factors
questions = re.findall(r"-s*(.*)", questions_text)
if not questions:
questions = [questions_text]
return questions
besides Exception as e:
print(f"Error extracting questions: {e}")
return []
# Operate to pick the highest questions
def top_questions(all_questions):
"""Generate the highest questions from the record of all questions."""
strive:
questions_text="n".be part of(f"- {query}" for query in all_questions)
immediate = (f"From the next record of questions extracted from prime articles about '{question}', "
f"choose the 5 most necessary questions that may be most helpful to the person. "
f"Checklist them as bullet factors.nn{questions_text}")
response = shopper.chat.completions.create(
messages=[
{"role": "system", "content": "You are an expert at identifying key questions on a topic."},
{"role": "user", "content": prompt}
],
mannequin="gpt-4o",
max_tokens=500,
temperature=0.1,
n=1
)
top_questions_text = response.selections[0].message.content material.strip()
# Cut up the response into particular person questions primarily based on bullet factors
top_questions_list = re.findall(r"-s*(.*)", top_questions_text)
if not top_questions_list:
top_questions_list = [top_questions_text]
return top_questions_list
besides Exception as e:
print(f"Error producing prime questions: {e}")
return []
# Operate to research entities utilizing Google Cloud NLP
def analyze_entities(text_content):
"""Analyze entities within the textual content utilizing Google Cloud NLP."""
strive:
doc = language_v1.Doc(content material=text_content, type_=language_v1.Doc.Kind.PLAIN_TEXT)
response = nlp_client.analyze_entities(doc=doc, encoding_type=language_v1.EncodingType.UTF8)
return response.entities
besides Exception as e:
print(f"Error analyzing entities: {e}")
return []Step 6: Scraping the highest 10 and accumulating the data
We’re nearly there. On this step, we use the capabilities above and ship our crawler throughout the highest 10 rating pages (you’ll be able to change this quantity).
We’re additionally going to put in writing a number of the core info to Weights & Biases so we will evaluation the varied inputs we’ve collected.
Once I confer with inputs, I imply the entities, questions and summaries we’ll use to reinforce our article define era immediate in step seven, our remaining step.
The code for this step is:
# Step 5: Scrape and analyze the highest rating pages
shopper = OpenAI()
# Initialize Weights & Biases
wandb.init(undertaking="wandb-article-outlines")
weave.init('wandb-article-outlines')
# Create W&B Tables to retailer scraped knowledge
firecrawl_table = wandb.Desk(columns=[
"url",
"markdown_summary",
"artifact_link",
"title",
"description",
"language",
"status_code"
])
top_questions_table = wandb.Desk(columns=[
"question"
])
entities_table = wandb.Desk(columns=[
"entity",
"aggregated_score",
"page_count"
])
# Initialize a listing to gather all questions, entities and summaries
all_questions = []
entity_data = {}
markdown_summaries = []
# Initialize Google Cloud NLP shopper
nlp_client = language_v1.LanguageServiceClient()
# Search and scrape prime 10 pages
search_results = google_search(question, google_api, google_search_id, num=10)
for lead to search_results:
url = end result['link']
print(f"Processing URL: {url}")
# Fetch content material utilizing Firecrawl
page_text = fetch_content_with_firecrawl(url)
if page_text is None:
print(f"Didn't fetch content material from {url}")
proceed # Skip if no content material
# Save the complete content material as a file
safe_title="".be part of(c if c.isalnum() else '_' for c in end result.get('title', 'page_text'))
artifact_filename = f"{safe_title}.txt"
with open(artifact_filename, 'w', encoding='utf-8') as f:
f.write(page_text)
# Create and log the artifact
artifact = wandb.Artifact(identify=f"page_text_{safe_title}", kind="page_text")
artifact.add_file(artifact_filename)
artifact = wandb.run.log_artifact(artifact) # Seize the logged artifact
artifact.wait()
artifact_link = artifact.get_entry(artifact_filename).ref_url
# Extract metadata
title = end result.get('title', 'Unknown Title')
description = end result.get('snippet', 'No description accessible')
language="en"
status_code = 200
# Extract headings from the markdown textual content
headings = extract_headings_from_markdown(page_text)
# Generate a abstract utilizing GPT-4
markdown_summary = generate_summary(page_text, headings)
if markdown_summary:
markdown_summaries.append(markdown_summary)
else:
print(f"No abstract generated for {url}")
# Extract questions from the web page and add them to the record
questions = extract_questions(page_text)
all_questions.lengthen(questions)
# Analyze entities within the web page textual content
entities = analyze_entities(page_text)
page_entities = set() # To trace distinctive entities on this web page
for entity in entities:
entity_name = entity.identify
salience = entity.salience
# Replace entity knowledge
if entity_name in entity_data:
entity_info = entity_data[entity_name]
entity_info['total_salience'] += salience
if url not in entity_info['pages']:
entity_info['page_count'] += 1
entity_info['pages'].add(url)
else:
entity_data[entity_name] = {
'total_salience': salience,
'page_count': 1,
'pages': {url}
}
# Add knowledge to the desk, together with the markdown abstract and artifact hyperlink
firecrawl_table.add_data(
url,
markdown_summary,
artifact_link,
title,
description,
language,
status_code
)
# Clear up the momentary file
os.take away(artifact_filename)
# After processing all pages, generate the highest questions
top_questions_list = top_questions(all_questions)
# Add the highest inquiries to the desk
for query in top_questions_list:
top_questions_table.add_data(query)
# Decide the highest entities
# Calculate a mixed rating: total_salience * page_count
for entity_name, knowledge in entity_data.gadgets():
aggregated_score = knowledge['total_salience'] * knowledge['page_count']
knowledge['aggregated_score'] = aggregated_score
# Kind entities by the aggregated rating
top_entities = sorted(entity_data.gadgets(), key=lambda merchandise: merchandise[1]['aggregated_score'], reverse=True)
# Get the highest N entities (e.g., prime 10)
top_n = 10
top_entities = top_entities[:top_n]
# Add prime entities to the entities desk
for entity_name, knowledge in top_entities:
entities_table.add_data(
entity_name,
knowledge['aggregated_score'],
knowledge['page_count']
)
# Log the tables to W&B
wandb.log({
"scraped_data": firecrawl_table,
"top_questions_table": top_questions_table,
"entities_table": entities_table,
"markdown_summaries": markdown_summaries,
})
print("Markdown Summaries:", markdown_summaries)
# End the W&B run
wandb.end()The cell will take a couple of minutes to complete operating, and when it does, you’ll see one thing like:
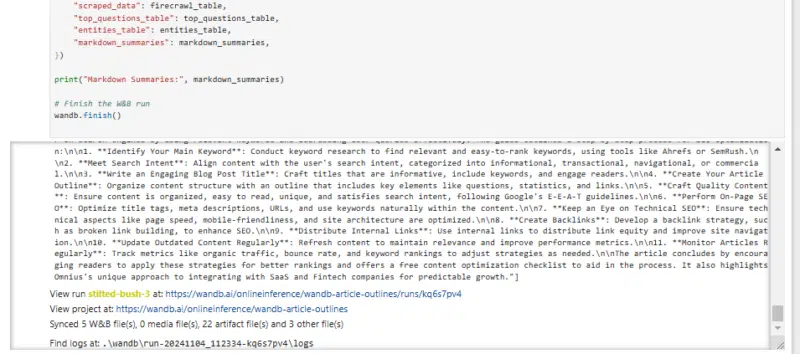
The system shows entities, questions, and summaries immediately on the display after a run.
Nonetheless, I want an easier strategy: clicking the Final run hyperlink to view the outcomes as a substitute.
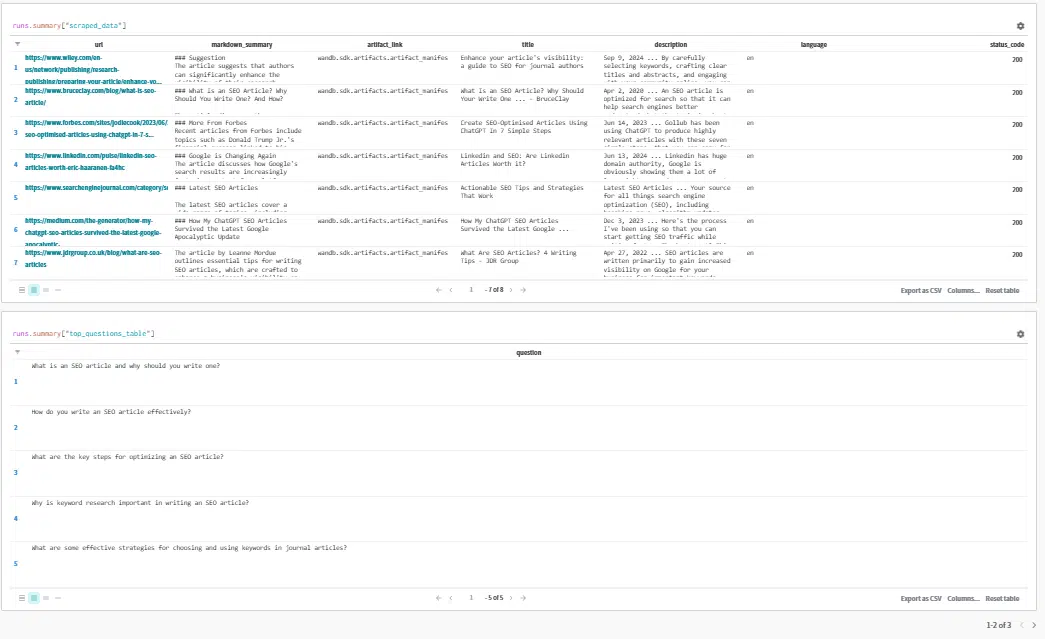
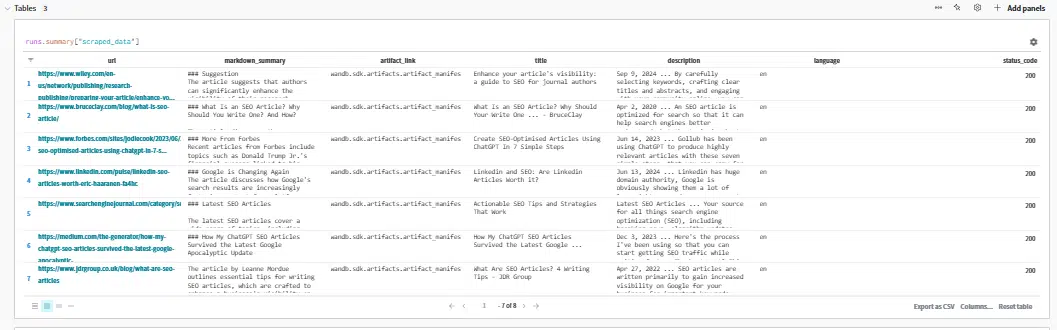
Right here, we will evaluation the output being handed to the immediate. This may help establish the place issues could go awry when you’re discovering your outlines aren’t fairly proper.
Step 7: Producing our article define
Now we will generate the article define.
I invite you to evaluation and edit the immediate to swimsuit the codecs you’ve discovered useful.
The one right here is pretty generic. It’s primarily based on codecs and guidelines I’ve discovered profitable, however with some specifics to particular person use instances eliminated.
The code to create the define is:
# Generate the article define utilizing the collected knowledge
@weave.op()
def generate_outline(top_entities, top_questions, question, query_secondary, article_type, markdown_summaries):
entities_str=", ".be part of([entity_name for entity_name, _ in top_entities])
questions_str=", ".be part of(top_questions)
summaries_str="nn".be part of(markdown_summaries)
strive:
response = shopper.chat.completions.create(
mannequin="gpt-4o",
messages=[
{"role": "system",
"content": "You create succinct and clear article outlines. You can include your understanding "
"of a topic to enhance an outline, but the focus should be on the inclusion of the entities, questions and top ranking content you are provided with."},
{"role": "assistant", "content": "You are a highly skilled writer and you want to produce a " + article_type +
" article outline that will appeal to users and rank well for queries given by the user. "
"The outline will contain headings and sub-headings, with clear and concise descriptions of the content "
"that is recommended for that section and why. n When you are recommending to create an introductory paragraph to a section, to capture a featured snippet, "
"note that it should be between 260 and 320 characters and then provide a clearly noted example of what one might be. "
"n After you have provided the outline, explain clearly how this article outline "
"could be used to create an article that will rank well using best-practice SEO strategies as well as be helpful "
"to users. You will be judged based on how well the article ranks, as well as how engaging the article is to readers, "
"and provide the metrics you would suggest be used to judge whether you are successful. n An example of an article "
"structure that works well is: nn"
"Title: Top-Level Content (e.g., An Introduction to [Main Topic])nn"
"The outline: Seen on the web page in addition to used as the outline to Google. Needs to be 130 <= character_count "
"<= 160 and embrace the principle key phrases every time potential.nn"
"**Introduction**nn"
"We do not want a heading tag right here. Merely dive in with a quick description of what you may be overlaying. One or two brief "
"paragraphs is nice, however longer is okay.nn"
"**H2 - Desk Of Contents**n"
"Ideally this part is completed manually, however in a pinch, you need to use the / Desk Of Contents function. You possibly can add a little bit of "
"further content material beneath the desk of contents when you like.nn"
"**H2 - What Is [Main Topic]?**n"
"Ideally right here we now have a piece on the principle matter. It can begin with a paragraph that runs between 230 and 260 characters. "
"This primary paragraph ought to be the brief reply to the query and it'll hopefully get picked up as a featured snippet "
"and be used for voice search. It may possibly and ought to be prolonged from there to offer further info and context.nn"
"**H2 - Optionally available - Subset Such As 'Varieties Of [Main Topic]'**n"
"Transient description here--ideally 230 to 260 characters.nn"
"**H3 - [Subset Type One] (e.g., First Subtype of [Main Topic])**n"
"Description of [Subset Type One]. Ideally beginning with 260 to 320 characters, however not obligatory and increasing from there.nn"
"**H3 - [Subset Type Two] (e.g., Second Subtype of [Main Topic])**n"
"Description of [Subset Type Two]. Ideally beginning with 260 to 320 characters, however not obligatory and increasing from there.nn"
"**H2 - A tutorial for [Main Topic]**n"
"Generate a tutorial primarily based on widespread macnmachine studying duties, that are doubtless discovered within the summaries supplied by the person. It's best to use W&B Weave every time potential.nn"
"**H2 - What Is [Main Topic] Used For?**n"
"Once more, ideally this begins with a 230 to 260 character brief reply and is expanded upon.nn"
"**H2 - Examples Of [Main Topic]** n"
"Optionally, we will place a quick description of the varieties of examples. It ought to be carried out in H3 tags (assuming it is a easy one). "
"A strong instance requiring a number of phases (e.g., setup, operating, visualizing) could require a number of H2 tags with H3s nested beneath.n"
"**H2 - Beneficial Studying On [Main Topic]** n"
"Right here we merely add a listing with 2 or 4 articles you are feeling are associated and can be of curiosity to the reader."},
{"function": "person",
"content material": "Create an article define that may rank properly for " + question + " as the first time period and " + query_secondary +
" secondary key phrases, that are much less necessary however ought to nonetheless be thought-about. The next entities look like "
"related to rating within the prime 10 and ought to be labored into the web page:n" + entities_str + "n Attempt to make sure the define "
"will make it straightforward to work these into the article prominently and clarify how this could be carried out in feedback. Moreover, "
"the next questions look like necessary to reply within the article:n" + questions_str +
"n The next are summaries of the content material and format that may be discovered on the top-ranking pages. This could closely affect "
"the outlines you produce, as this content material ranks properly: n" + summaries_str + "n"
"Attempt to make sure that it is going to be straightforward to reply these questions within the article and once more, clarify how you'll advocate "
"doing this in a means that may appear helpful to the person. The article define ought to start by explaining n- all the core "
"ideas required to grasp the subject"
}],
max_tokens=2000,
temperature=0.2,
n=1
)
return response.selections[0].message.content material.strip()
besides Exception as e:
print(f"Error producing define: {e}")
return "Define not accessible."
# Generate the article define
article_outline = generate_outline(
top_entities,
top_questions_list,
question,
query_secondary,
article_type,
markdown_summaries
)
# Optionally, you'll be able to print or save the article define
print("Generated Article Define:")
print(article_outline)You’ll get your define when you’ve run this (a few minute or so).
Should you take a look at the prompts, you’ll see that I’ve advised it to develop the article define utilizing the article kind we outlined in Step 1, in addition to the focused queries, prime query, entities and summaries.
As famous above, this enables us to generate articles impressed by what’s engaged on the best-performing websites.
The default output seems to be like this:
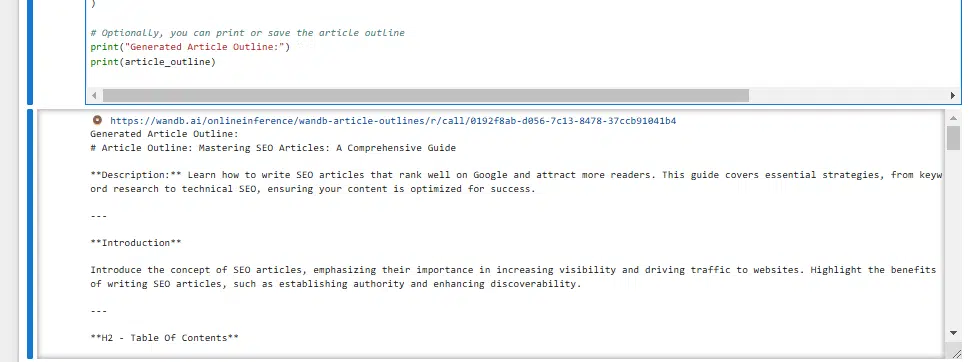
But when we click on the hyperlink on the prime, we’re moved into W&B Weave, the place we will contextualize that define.
The GIF beneath illustrates how we will evaluation the entities and their salience scores, prime questions, URL summaries, queries and article varieties alongside the output (the define) for troubleshooting and to grasp the data used to generate the define.
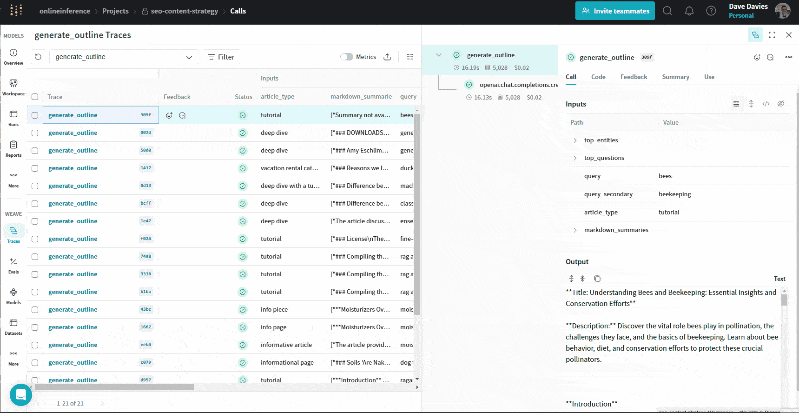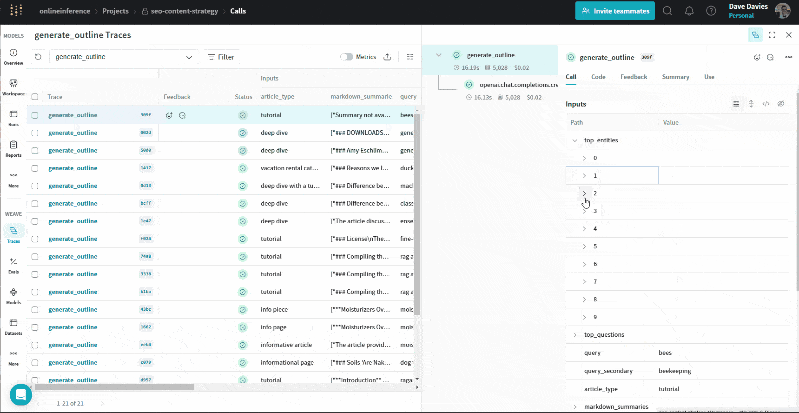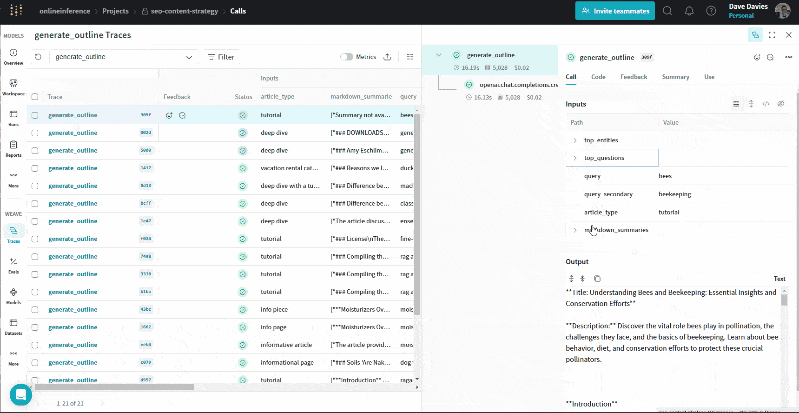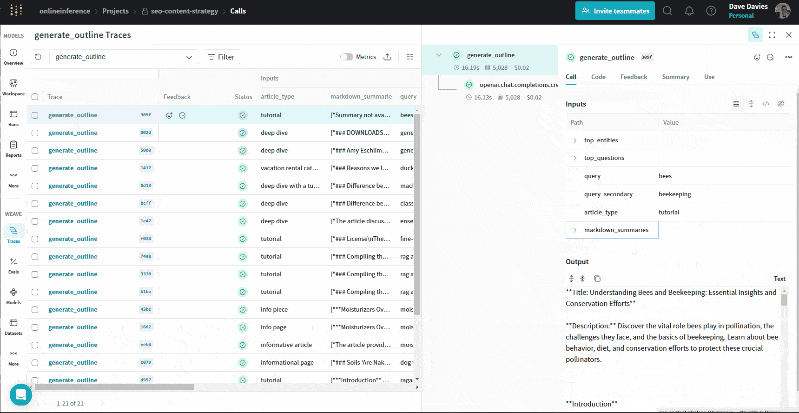
Just the start
Hopefully you discover this script and its options as helpful as I do. I additionally hope you don’t simply use the script with out making any modifications.
Discover easy methods to modify the prompts, add to them and possibly even take into consideration completely different APIs you can complement the information with.
I’m already engaged on some new enhancements. I’d love to listen to your concepts.
Contributing authors are invited to create content material for Search Engine Land and are chosen for his or her experience and contribution to the search neighborhood. Our contributors work below the oversight of the editorial workers and contributions are checked for high quality and relevance to our readers. The opinions they specific are their very own.