

{kind=link}
Understanding the distinction between search bots and scrapers is essential for Web optimization.
Web site crawlers fall into two classes:
- First-party bots, which you employ to audit and optimize your individual website.
- Third-party bots, which crawl your website externally – generally to index your content material (like Googlebot) and different instances to extract knowledge (like competitor scrapers).
This information breaks down first-party crawlers that may enhance your website’s technical Web optimization and third-party bots, exploring their affect and find out how to handle them successfully.
First-party crawlers: Mining insights from your individual web site
Crawlers can assist you determine methods to enhance your technical Web optimization.
Enhancing your website’s technical basis, architectural depth, and crawl effectivity is a long-term technique for rising search site visitors.
Often, you could uncover main points – equivalent to a robots.txt file blocking all search bots on a staging website that was left lively after launch.
Fixing such issues can result in speedy enhancements in search visibility.
Now, let’s discover some crawl-based applied sciences you should use.
Googlebot through Search Console
You don’t work in a Google knowledge heart, so you may’t launch Googlebot to crawl your individual website.
Nonetheless, by verifying your website with Google Search Console (GSC), you may entry Googlebot’s knowledge and insights. (Observe Google’s steerage to set your self up on the platform.)
GSC is free to make use of and offers useful data – particularly about web page indexing.
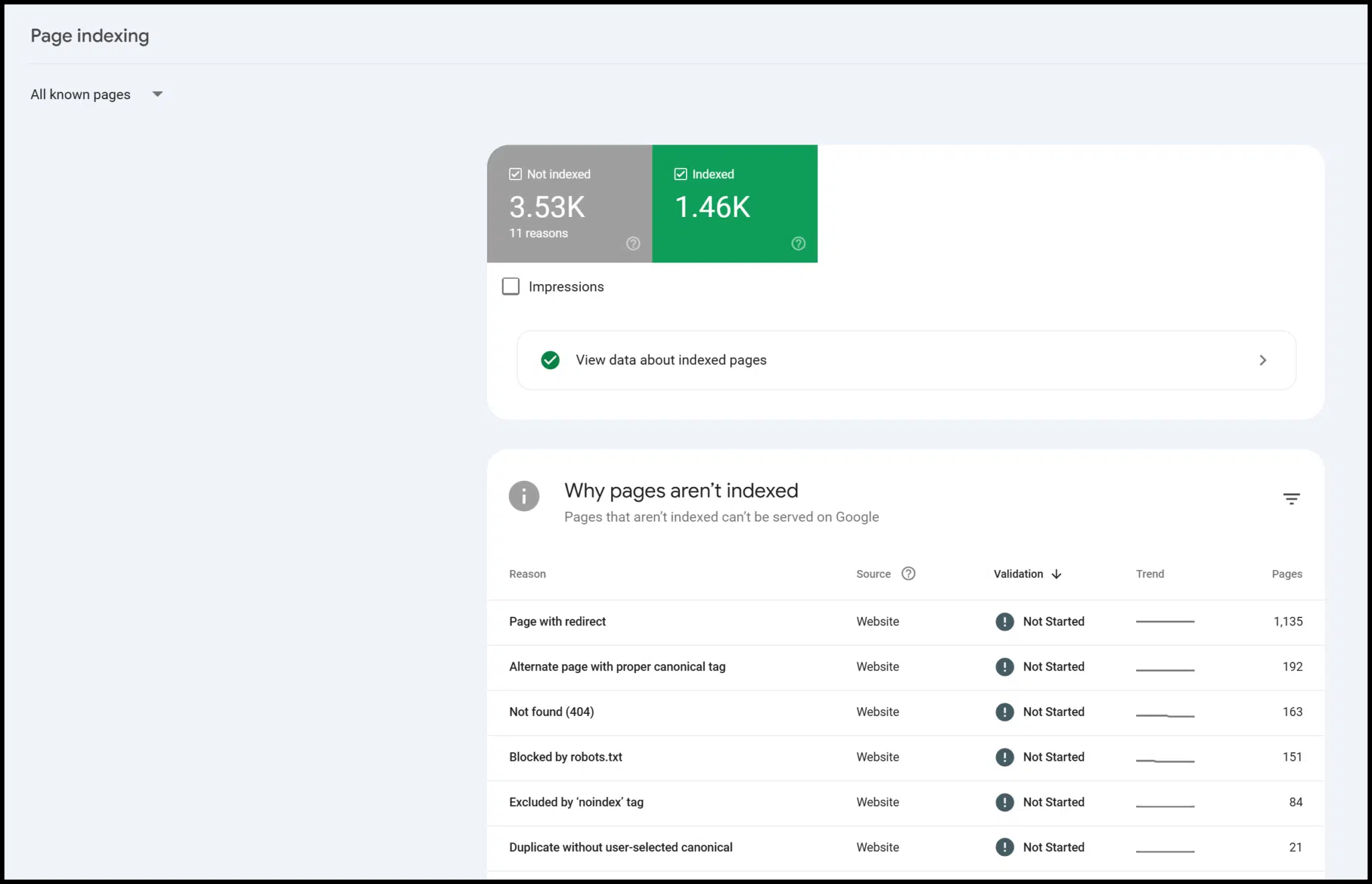
There’s additionally knowledge on mobile-friendliness, structured knowledge, and Core Net Vitals:
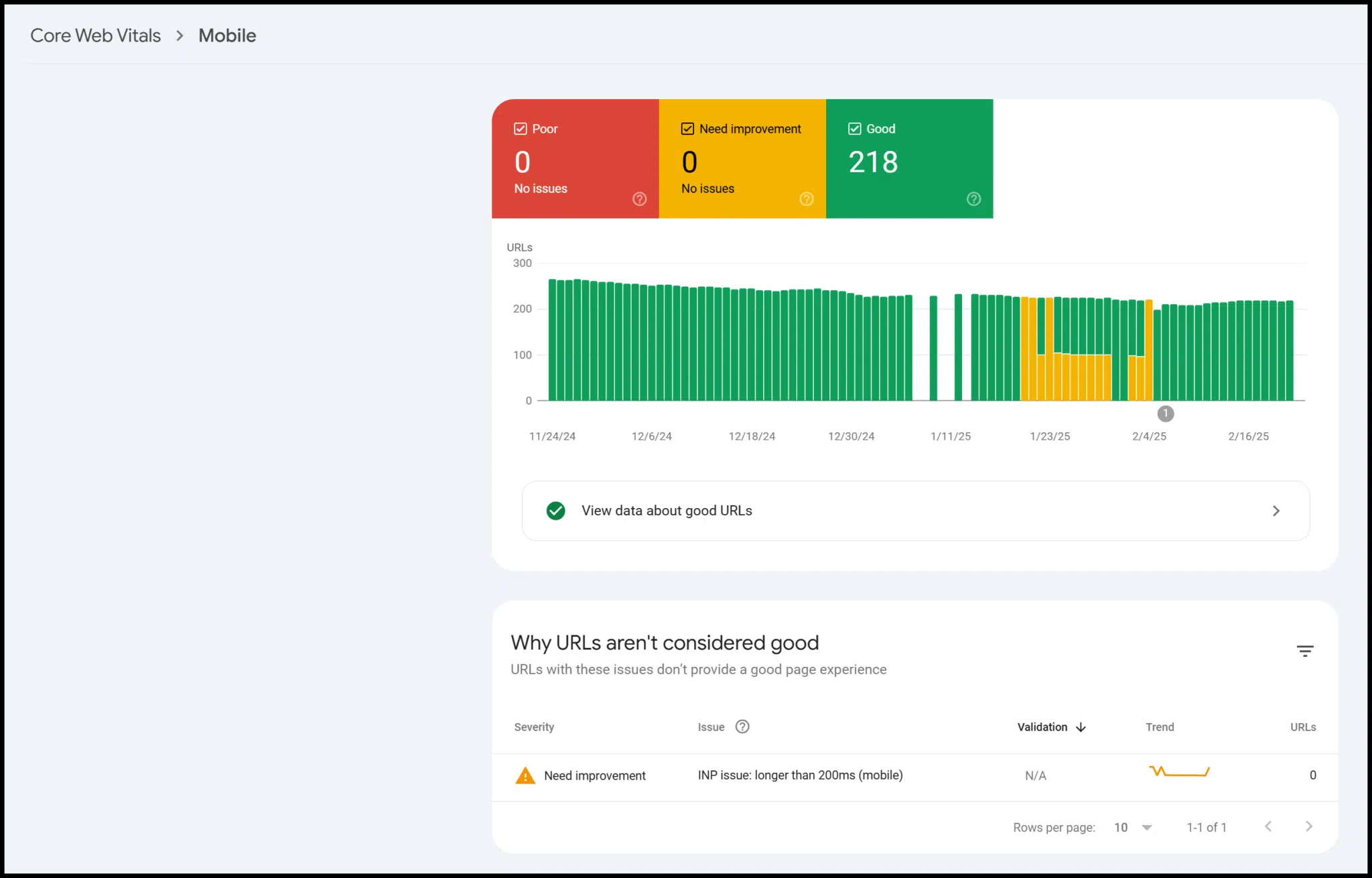
Technically, that is third-party knowledge from Google, however solely verified customers can entry it for his or her website.
In follow, it capabilities very similar to the information from a crawl you run your self.
Screaming Frog Web optimization Spider
Screaming Frog is a desktop utility that runs regionally in your machine to generate crawl knowledge in your web site.
Additionally they supply a log file analyzer, which is beneficial when you have entry to server log recordsdata. For now, we’ll concentrate on Screaming Frog’s Web optimization Spider.
At $259 per yr, it’s extremely cost-effective in comparison with different instruments that cost this a lot per 30 days.
Nonetheless, as a result of it runs regionally, crawling stops in the event you flip off your laptop – it doesn’t function within the cloud.
Nonetheless, the information it offers is quick, correct, and preferrred for many who wish to dive deeper into technical Web optimization.
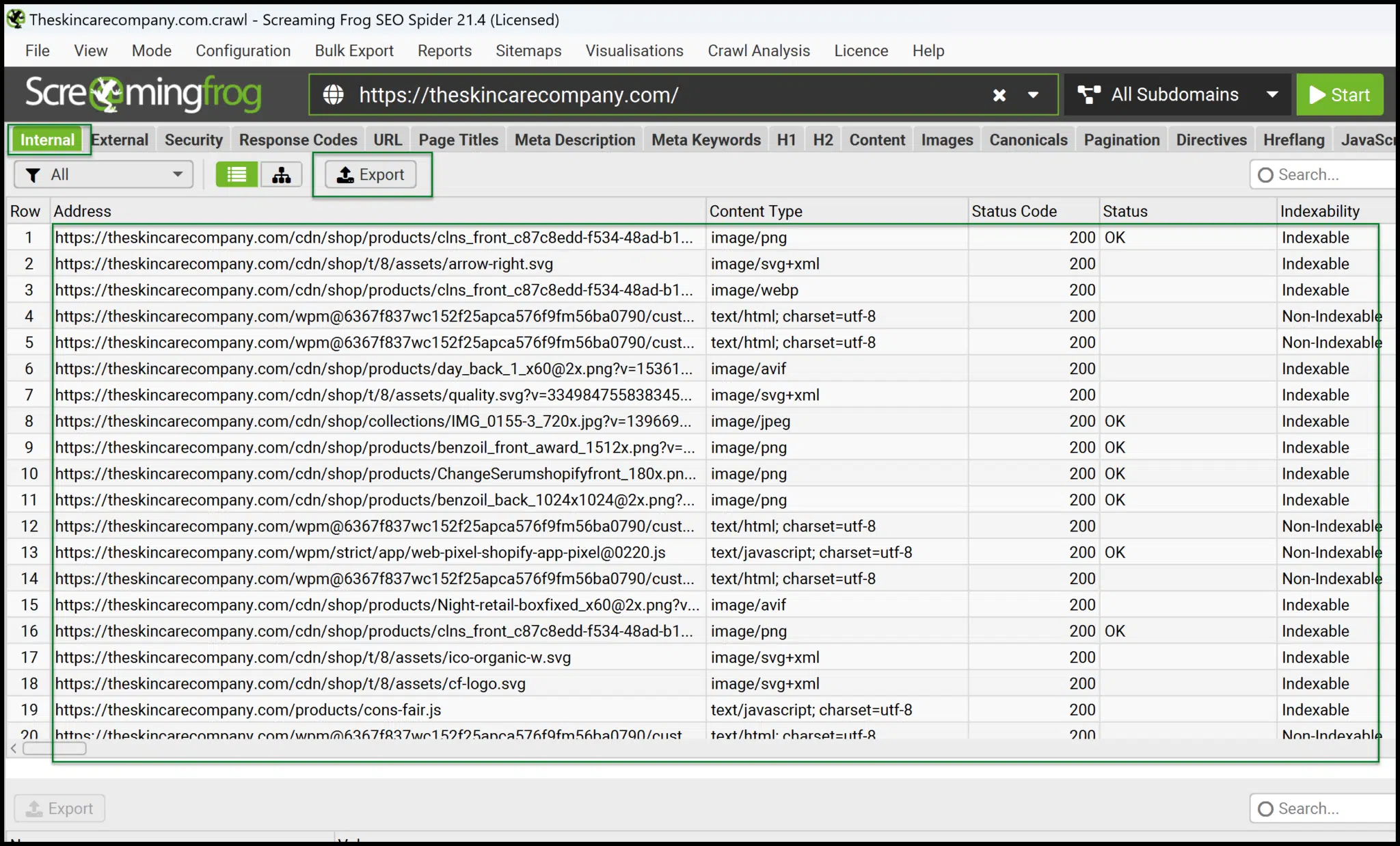
From the primary interface, you may shortly launch your individual crawls.
As soon as accomplished, export Inside > All knowledge to an Excel-readable format and get comfy dealing with and pivoting the information for deeper insights.
Screaming Frog additionally provides many different helpful export choices.
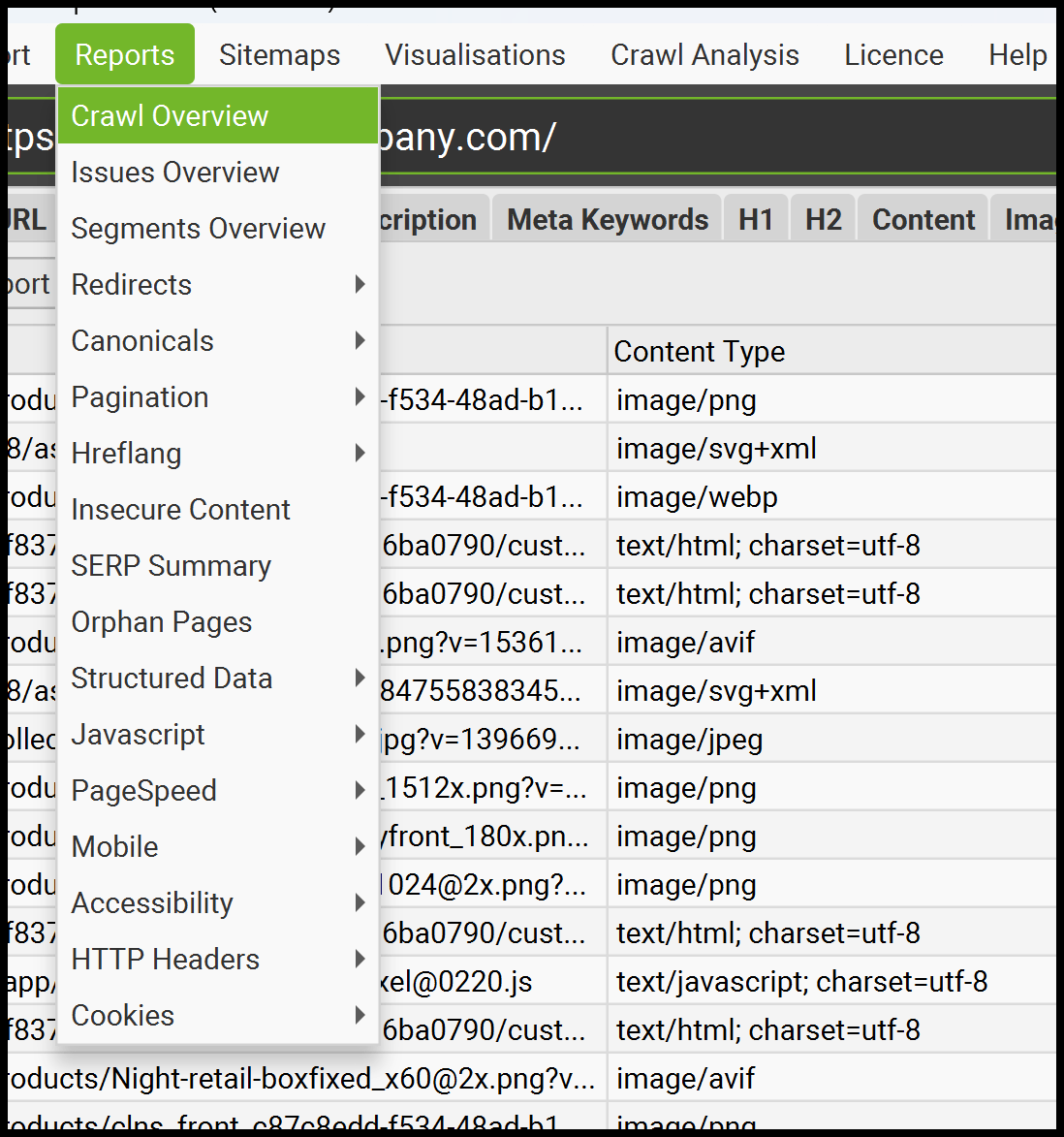
It offers studies and exports for inner linking, redirects (together with redirect chains), insecure content material (blended content material), and extra.
The disadvantage is it requires extra hands-on administration, and also you’ll have to be comfy working with knowledge in Excel or Google Sheets to maximise its worth.
Dig deeper: 4 of the most effective technical Web optimization instruments
Ahrefs Website Audit
Ahrefs is a complete cloud-based platform that features a technical Web optimization crawler inside its Website Audit module.
To make use of it, arrange a challenge, configure the crawl parameters, and launch the crawl to generate technical Web optimization insights.
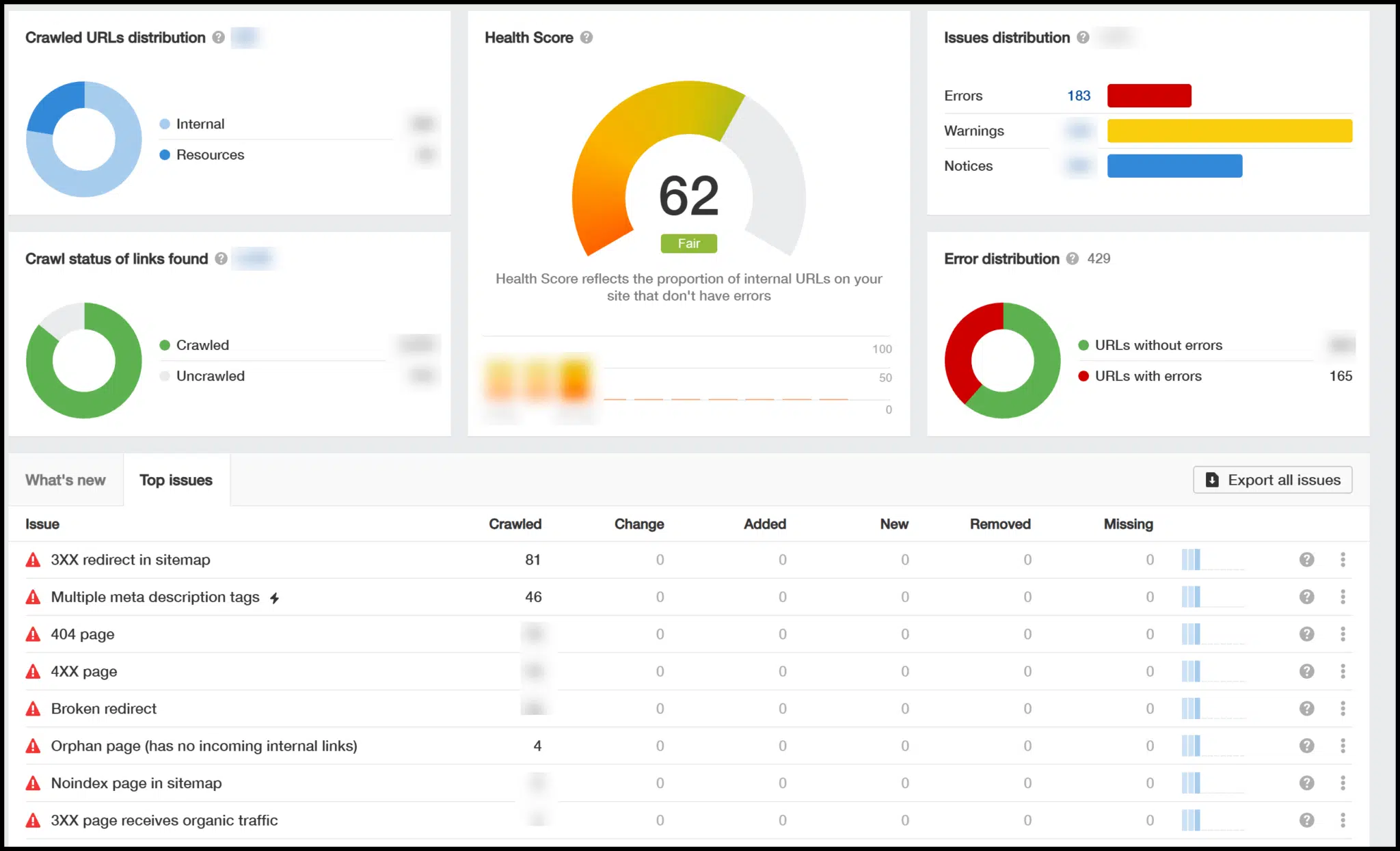
As soon as the crawl is full, you’ll see an outline that features a technical Web optimization well being score (0-100) and highlights key points.
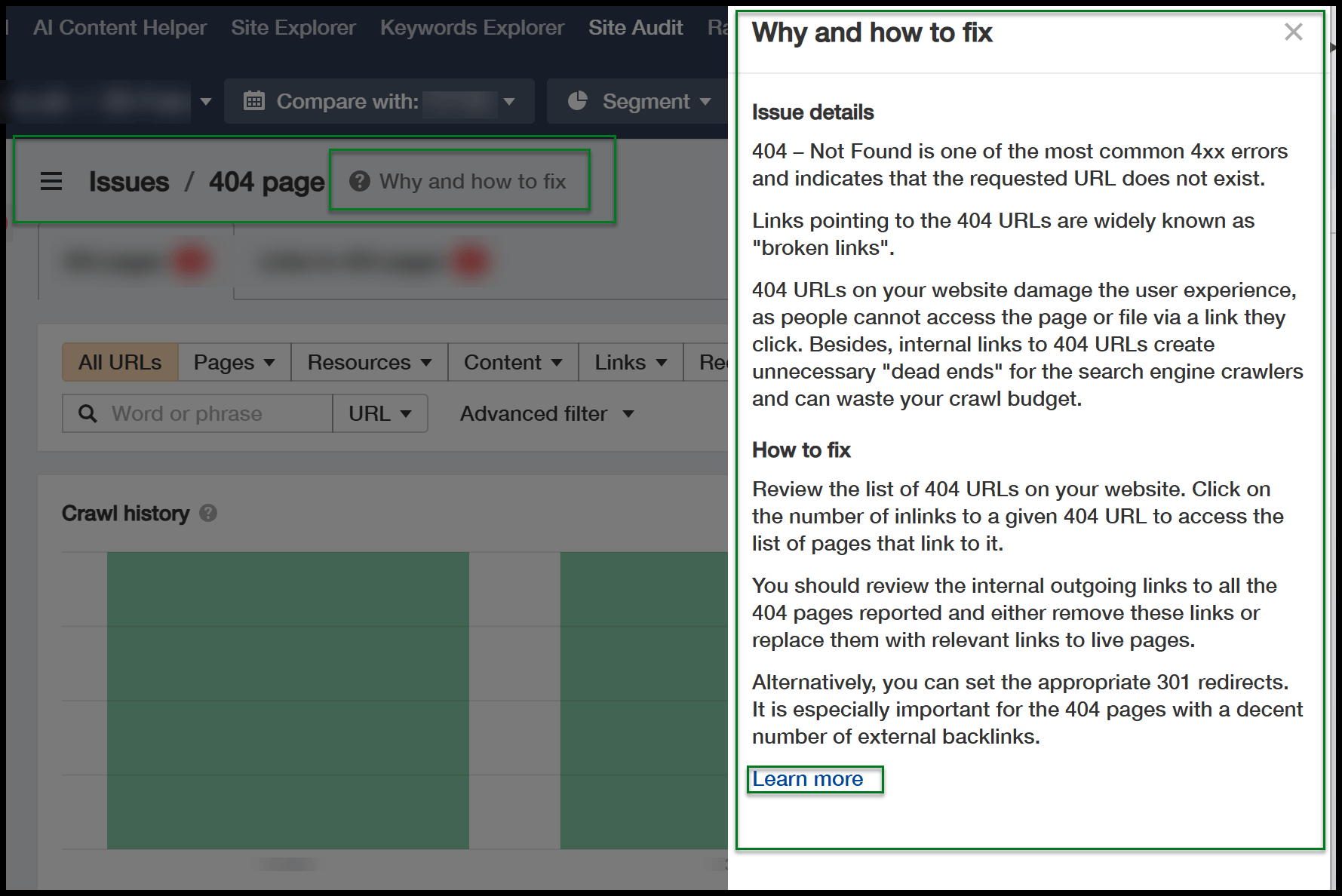
You’ll be able to click on on these points for extra particulars, and a useful button seems as you dive deeper, explaining why sure fixes are vital.
Since Ahrefs runs within the cloud, your machine’s standing doesn’t have an effect on the crawl. It continues even when your PC or Mac is turned off.
In comparison with Screaming Frog, Ahrefs offers extra steerage, making it simpler to show crawl knowledge into actionable Web optimization insights.
Nonetheless, it’s much less cost-effective. Should you don’t want its further options, like backlink knowledge and key phrase analysis, it will not be well worth the expense.
Semrush Website Audit
Subsequent is Semrush, one other highly effective cloud-based platform with a built-in technical Web optimization crawler.
Like Ahrefs, it additionally offers backlink evaluation and key phrase analysis instruments.
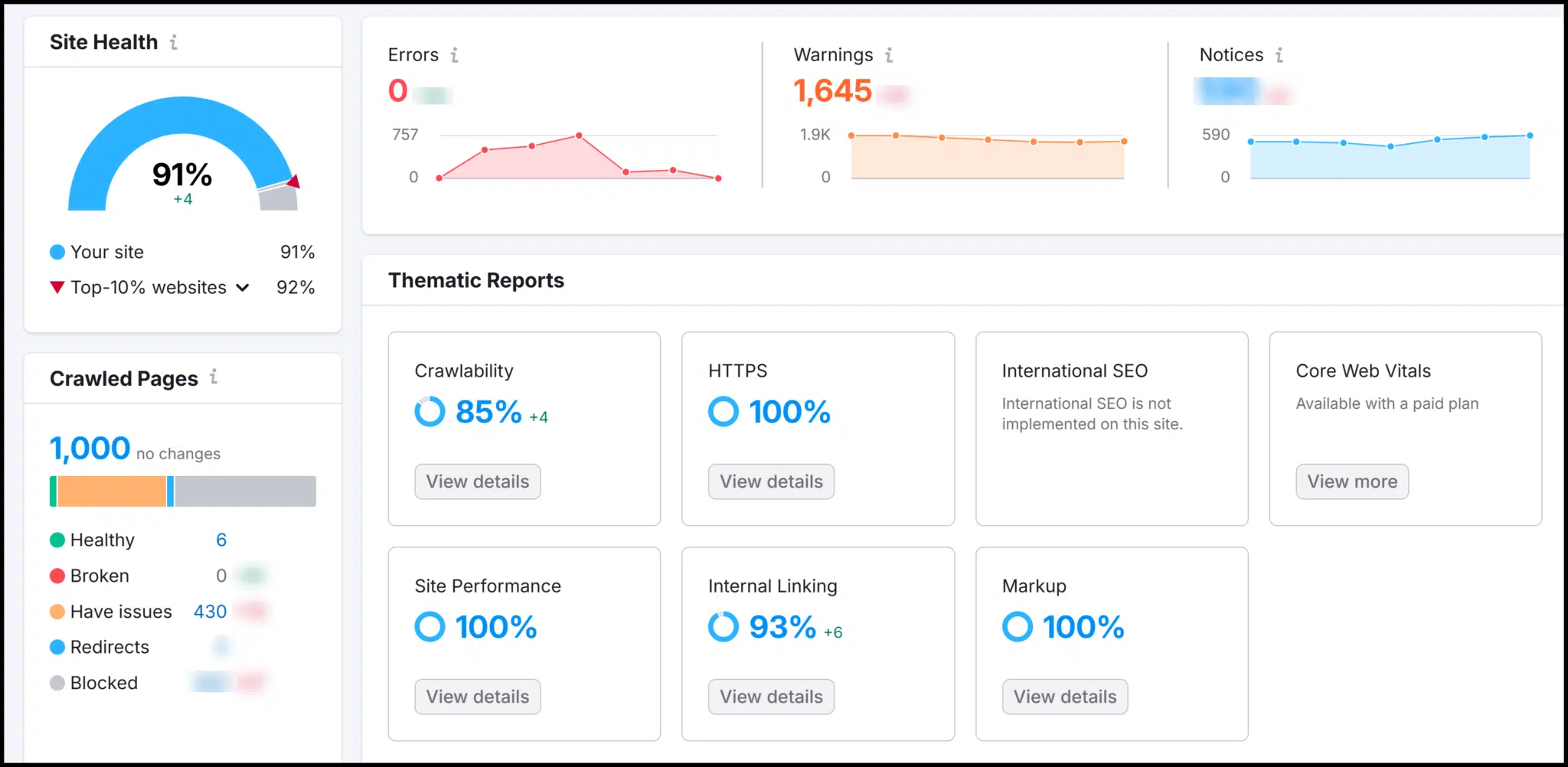
Semrush provides a technical Web optimization well being score, which improves as you repair website points. Its crawl overview highlights errors and warnings.
As you discover, you’ll discover explanations of why fixes are wanted and find out how to implement them.
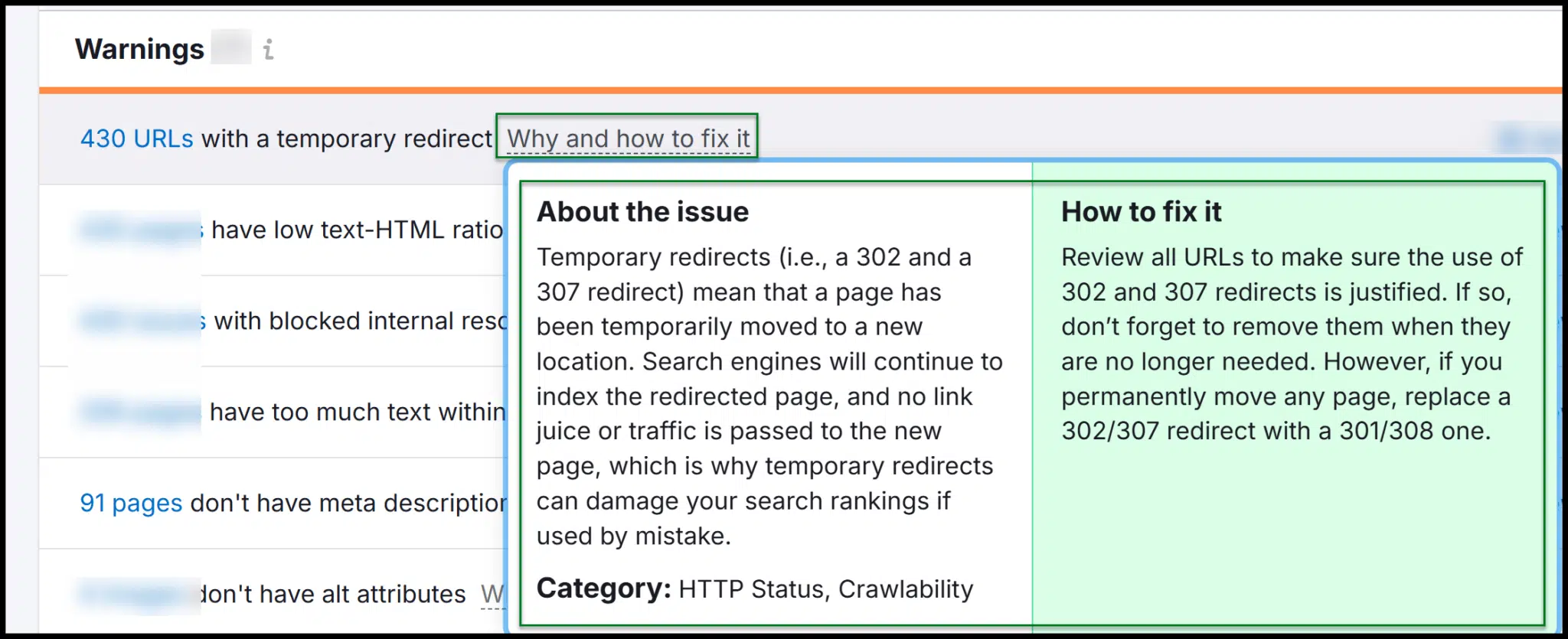
Each Semrush and Ahrefs have strong website audit instruments, making it straightforward to launch crawls, analyze knowledge, and supply suggestions to builders.
Whereas each platforms are pricier than Screaming Frog, they excel at turning crawl knowledge into actionable insights.
Semrush is barely cheaper than Ahrefs, making it a strong alternative for these new to technical Web optimization.
Get the publication search entrepreneurs depend on.
Third-party crawlers: Bots that may go to your web site
Earlier, we mentioned how third events would possibly crawl your web site for varied causes.
However what are these exterior crawlers, and how are you going to determine them?
Googlebot
As talked about, you should use Google Search Console to entry a few of Googlebot’s crawl knowledge in your website.
With out Googlebot crawling your website, there could be no knowledge to investigate.
(You’ll be able to study extra about Google’s frequent crawl bots on this Search Central documentation.)
Google’s most typical crawlers are:
- Googlebot Smartphone.
- Googlebot Desktop.
Every makes use of separate rendering engines for cellular and desktop, however each comprise “Googlebot/2.1” of their user-agent string.
Should you analyze your server logs, you may isolate Googlebot site visitors to see which areas of your website it crawls most steadily.
This can assist determine technical Web optimization points, equivalent to pages that Google isn’t crawling as anticipated.
To investigate log recordsdata, you may create spreadsheets to course of and pivot the information from uncooked .txt or .csv recordsdata. If that appears complicated, Screaming Frog’s Log File Analyzer is a great tool.
Most often, you shouldn’t block Googlebot, as this could negatively have an effect on Web optimization.
Nonetheless, if Googlebot will get caught in extremely dynamic website structure, you could want to dam particular URLs through robots.txt. Use this fastidiously – overuse can hurt your rankings.
Faux Googlebot site visitors
Not all site visitors claiming to be Googlebot is authentic.
Many crawlers and scrapers enable customers to spoof user-agent strings, which means they will disguise themselves as Googlebot to bypass crawl restrictions.
For instance, Screaming Frog may be configured to impersonate Googlebot.
Nonetheless, many web sites – particularly these hosted on giant cloud networks like AWS – can differentiate between actual and pretend Googlebot site visitors.
They do that by checking if the request comes from Google’s official IP ranges.
If a request claims to be Googlebot however originates exterior of these ranges, it’s doubtless pretend.
Different search engines like google
Along with Googlebot, different search engines like google might crawl your website. For instance:
- Bingbot (Microsoft Bing).
- DuckDuckBot (DuckDuckGo).
- YandexBot (Yandex, a Russian search engine, although not well-documented).
- Baiduspider (Baidu, a well-liked search engine in China).
In your robots.txt file, you may create wildcard guidelines to disallow all search bots or specify guidelines for explicit crawlers and directories.
Nonetheless, take into account that robots.txt entries are directives, not instructions – which means they are often ignored.
Not like redirects, which stop a server from serving a useful resource, robots.txt is merely a powerful sign requesting bots to not crawl sure areas.
Some crawlers might disregard these directives fully.
Screaming Frog’s Crawl Bot
Screaming Frog usually identifies itself with a person agent like Screaming Frog Web optimization Spider/21.4.
The “Screaming Frog Web optimization Spider” textual content is all the time included, adopted by the model quantity.
Nonetheless, Screaming Frog permits customers to customise the user-agent string, which means crawls can look like from Googlebot, Chrome, or one other user-agent.
This makes it troublesome to dam Screaming Frog crawls.
When you can block person brokers containing “Screaming Frog Web optimization Spider,” an operator can merely change the string.
Should you suspect unauthorized crawling, you could have to determine and block the IP vary as an alternative.
This requires server-side intervention out of your net developer, as robots.txt can not block IPs – particularly since Screaming Frog may be configured to disregard robots.txt directives.
Be cautious, although. It is perhaps your individual Web optimization workforce conducting a crawl to verify for technical Web optimization points.
Earlier than blocking Screaming Frog, attempt to decide the supply of the site visitors, because it could possibly be an inner worker gathering knowledge.
Ahrefs Bot
Ahrefs has a crawl bot and a website audit bot for crawling.
- When Ahrefs crawls the net for its personal index, you’ll see site visitors from
AhrefsBot/7.0. - When an Ahrefs person runs a website audit, site visitors will come from
AhrefsSiteAudit/6.1.
Each bots respect robots.txt disallow guidelines, per Ahrefs’ documentation.
Should you don’t need your website to be crawled, you may block Ahrefs utilizing robots.txt.
Alternatively, your net developer can deny requests from person brokers containing “AhrefsBot” or “AhrefsSiteAudit“.
Semrush Bot
Like Ahrefs, Semrush operates a number of crawlers with totally different user-agent strings.
Make sure you overview all obtainable data to determine them correctly.
The 2 most typical user-agent strings you’ll encounter are:
- SemrushBot: Semrush’s common net crawler, used to enhance its index.
- SiteAuditBot: Used when a Semrush person initiates a website audit.
Rogerbot, Dotbot, and different crawlers
Moz, one other extensively used cloud-based Web optimization platform, deploys Rogerbot to crawl web sites for technical insights.
Moz additionally operates Dotbot, a common net crawler. Each may be blocked through your robots.txt file if wanted.
One other crawler you could encounter is MJ12Bot, utilized by the Majestic Web optimization platform. Sometimes, it’s nothing to fret about.
Non-Web optimization crawl bots
Not all crawlers are Web optimization-related. Many social platforms function their very own bots.
Meta (Fb’s guardian firm) runs a number of crawlers, whereas Twitter beforehand used Twitterbot – and it’s doubtless that X now deploys an identical, although less-documented, system.
Crawlers repeatedly scan the net for knowledge. Some can profit your website, whereas others must be monitored by means of server logs.
Understanding search bots, Web optimization crawlers and scrapers for technical Web optimization
Managing each first-party and third-party crawlers is important for sustaining your web site’s technical Web optimization.
Key takeaways
- First-party crawlers (e.g., Screaming Frog, Ahrefs, Semrush) assist audit and optimize your individual website.
- Googlebot insights through Search Console present essential knowledge on indexation and efficiency.
- Third-party crawlers (e.g., Bingbot, AhrefsBot, SemrushBot) crawl your website for search indexing or aggressive evaluation.
- Managing bots through robots.txt and server logs can assist management undesirable crawlers and enhance crawl effectivity in particular instances.
- Information dealing with abilities are essential for extracting significant insights from crawl studies and log recordsdata.
By balancing proactive auditing with strategic bot administration, you may guarantee your website stays well-optimized and effectively crawled.
Contributing authors are invited to create content material for Search Engine Land and are chosen for his or her experience and contribution to the search group. Our contributors work below the oversight of the editorial employees and contributions are checked for high quality and relevance to our readers. The opinions they categorical are their very own.