
 (September 2024)")
{kind=link}
The sector of synthetic intelligence is evolving at a panoramic tempo, with giant language fashions (LLMs) main the cost in pure language processing and understanding. As we navigate this, a brand new era of LLMs has emerged, every pushing the boundaries of what is potential in AI.
On this overview of the very best LLMs, we’ll discover the important thing options, benchmark performances, and potential functions of those cutting-edge language fashions, providing insights into how they’re shaping the way forward for AI know-how.
Anthropic’s Claude 3 fashions, launched in March 2024, represented a big leap ahead in synthetic intelligence capabilities. This household of LLMs affords enhanced efficiency throughout a variety of duties, from pure language processing to complicated problem-solving.
Claude 3 is available in three distinct variations, every tailor-made for particular use instances:
- Claude 3 Opus: The flagship mannequin, providing the very best degree of intelligence and functionality.
- Claude 3.5 Sonnet: A balanced choice, offering a mixture of pace and superior performance.
- Claude 3 Haiku: The quickest and most compact mannequin, optimized for fast responses and effectivity.
Key Capabilites of Claude 3:
- Enhanced Contextual Understanding: Claude 3 demonstrates improved capability to know nuanced contexts, lowering pointless refusals and higher distinguishing between probably dangerous and benign requests.
- Multilingual Proficiency: The fashions present vital enhancements in non-English languages, together with Spanish, Japanese, and French, enhancing their international applicability.
- Visible Interpretation: Claude 3 can analyze and interpret numerous forms of visible information, together with charts, diagrams, pictures, and technical drawings.
- Superior Code Era and Evaluation: The fashions excel at coding duties, making them worthwhile instruments for software program growth and information science.
- Giant Context Window: Claude 3 incorporates a 200,000 token context window, with potential for inputs over 1 million tokens for choose high-demand functions.
Benchmark Efficiency:
Claude 3 Opus has demonstrated spectacular outcomes throughout numerous industry-standard benchmarks:
- MMLU (Huge Multitask Language Understanding): 86.7%
- GSM8K (Grade Faculty Math 8K): 94.9%
- HumanEval (coding benchmark): 90.6%
- GPQA (Graduate-level Skilled High quality Assurance): 66.1%
- MATH (superior mathematical reasoning): 53.9%
These scores typically surpass these of different main fashions, together with GPT-4 and Google’s Gemini Extremely, positioning Claude 3 as a high contender within the AI panorama.
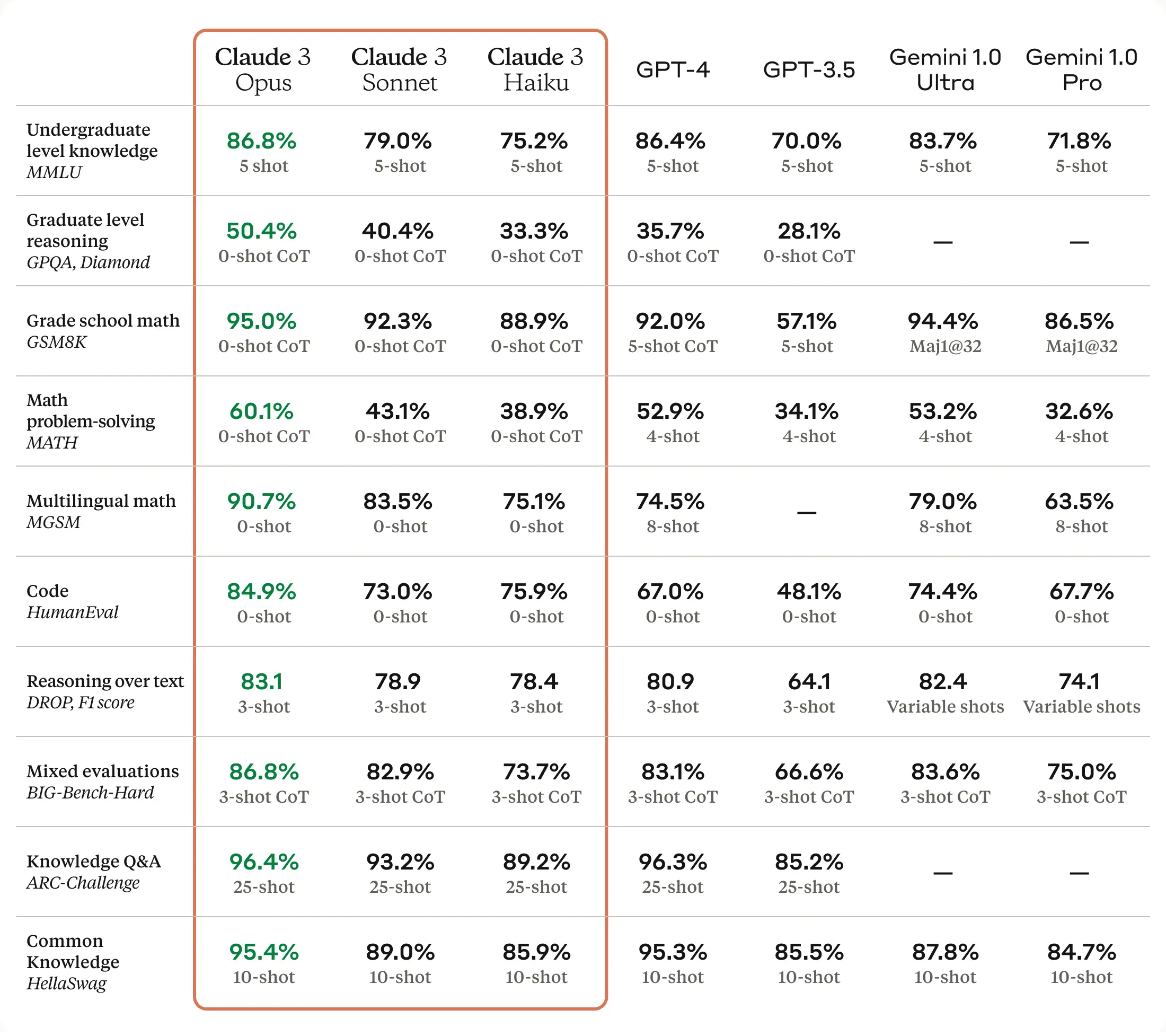
Claude 3 Benchmarks (Anthropic)
Claude 3 Moral Concerns and Security
Anthropic has positioned a robust emphasis on AI security and ethics within the growth of Claude 3:
- Lowered Bias: The fashions present improved efficiency on bias-related benchmarks.
- Transparency: Efforts have been made to boost the general transparency of the AI system.
- Steady Monitoring: Anthropic maintains ongoing security monitoring, with Claude 3 reaching an AI Security Degree 2 score.
- Accountable Growth: The corporate stays dedicated to advancing security and neutrality in AI growth.
Claude 3 represents a big development in LLM know-how, providing improved efficiency throughout numerous duties, enhanced multilingual capabilities, and complex visible interpretation. Its robust benchmark outcomes and versatile functions make it a compelling selection for an LLM.
OpenAI’s GPT-4o (“o” for “omni”) affords improved efficiency throughout numerous duties and modalities, representing a brand new frontier in human-computer interplay.
Key Capabilities:
- Multimodal Processing: GPT-4o can settle for inputs and generate outputs in a number of codecs, together with textual content, audio, photos, and video, permitting for extra pure and versatile interactions.
- Enhanced Language Understanding: The mannequin matches GPT-4 Turbo’s efficiency on English textual content and code duties whereas providing superior efficiency in non-English languages.
- Actual-time Interplay: GPT-4o can reply to audio inputs in as little as 232 milliseconds, with a mean of 320 milliseconds, corresponding to human dialog response instances.
- Improved Imaginative and prescient Processing: The mannequin demonstrates enhanced capabilities in understanding and analyzing visible inputs in comparison with earlier variations.
- Giant Context Window: GPT-4o incorporates a 128,000 token context window, permitting for processing of longer inputs and extra complicated duties.
Efficiency and Effectivity:
- Pace: GPT-4o is twice as quick as GPT-4 Turbo.
- Price-efficiency: It’s 50% cheaper in API utilization in comparison with GPT-4 Turbo.
- Price limits: GPT-4o has 5 instances greater price limits in comparison with GPT-4 Turbo.
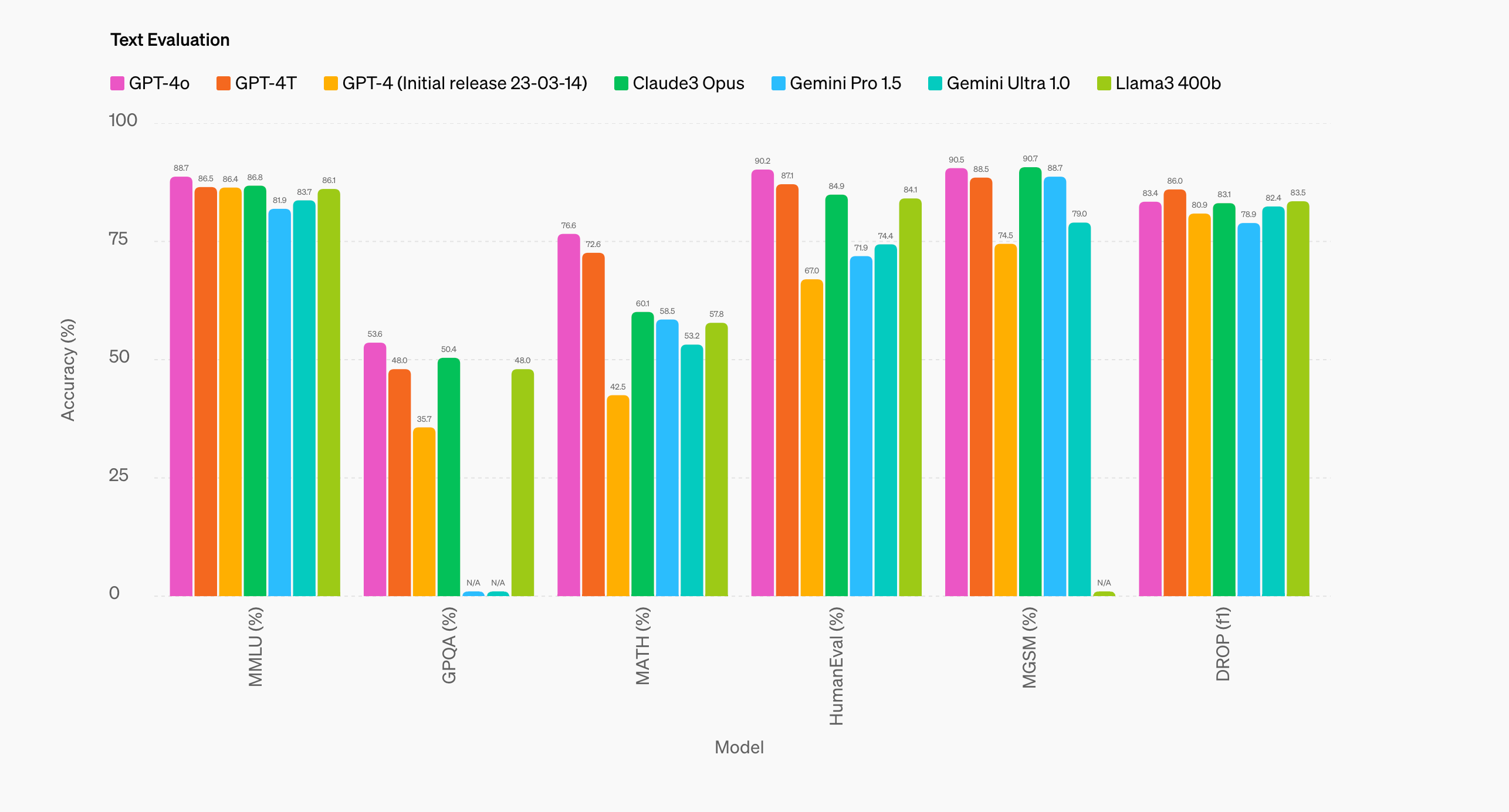
GPT-4o benchmarks (OpenAI)
GPT-4o’s versatile capabilities make it appropriate for a variety of functions, together with:
- Pure language processing and era
- Multilingual communication and translation
- Picture and video evaluation
- Voice-based interactions and assistants
- Code era and evaluation
- Multimodal content material creation
Availability:
- ChatGPT: Out there to each free and paid customers, with greater utilization limits for Plus subscribers.
- API Entry: Out there by way of OpenAI’s API for builders.
- Azure Integration: Microsoft affords GPT-4o by way of Azure OpenAI Service.
GPT-4o Security and Moral Concerns
OpenAI has applied numerous security measures for GPT-4o:
- Constructed-in security options throughout modalities
- Filtering of coaching information and refinement of mannequin conduct
- New security methods for voice outputs
- Analysis in accordance with OpenAI’s Preparedness Framework
- Compliance with voluntary commitments to accountable AI growth
GPT-4o affords enhanced capabilities throughout numerous modalities whereas sustaining a concentrate on security and accountable deployment. Its improved efficiency, effectivity, and flexibility make it a robust instrument for a variety of functions, from pure language processing to complicated multimodal duties.
Llama 3.1 is the newest household of enormous language fashions by Meta and affords improved efficiency throughout numerous duties and modalities, difficult the dominance of closed-source alternate options.
Llama 3.1 is offered in three sizes, catering to completely different efficiency wants and computational assets:
- Llama 3.1 405B: Probably the most highly effective mannequin with 405 billion parameters
- Llama 3.1 70B: A balanced mannequin providing robust efficiency
- Llama 3.1 8B: The smallest and quickest mannequin within the household
Key Capabilities:
- Enhanced Language Understanding: Llama 3.1 demonstrates improved efficiency basically information, reasoning, and multilingual duties.
- Prolonged Context Window: All variants characteristic a 128,000 token context window, permitting for processing of longer inputs and extra complicated duties.
- Multimodal Processing: The fashions can deal with inputs and generate outputs in a number of codecs, together with textual content, audio, photos, and video.
- Superior Device Use: Llama 3.1 excels at duties involving instrument use, together with API interactions and performance calling.
- Improved Coding Skills: The fashions present enhanced efficiency in coding duties, making them worthwhile for builders and information scientists.
- Multilingual Help: Llama 3.1 affords improved capabilities throughout eight languages, enhancing its utility for international functions.
Llama 3.1 Benchmark Efficiency
Llama 3.1 405B has proven spectacular outcomes throughout numerous benchmarks:
- MMLU (Huge Multitask Language Understanding): 88.6%
- HumanEval (coding benchmark): 89.0%
- GSM8K (Grade Faculty Math 8K): 96.8%
- MATH (superior mathematical reasoning): 73.8%
- ARC Problem: 96.9%
- GPQA (Graduate-level Skilled High quality Assurance): 51.1%
These scores display Llama 3.1 405B’s aggressive efficiency in opposition to high closed-source fashions in numerous domains.
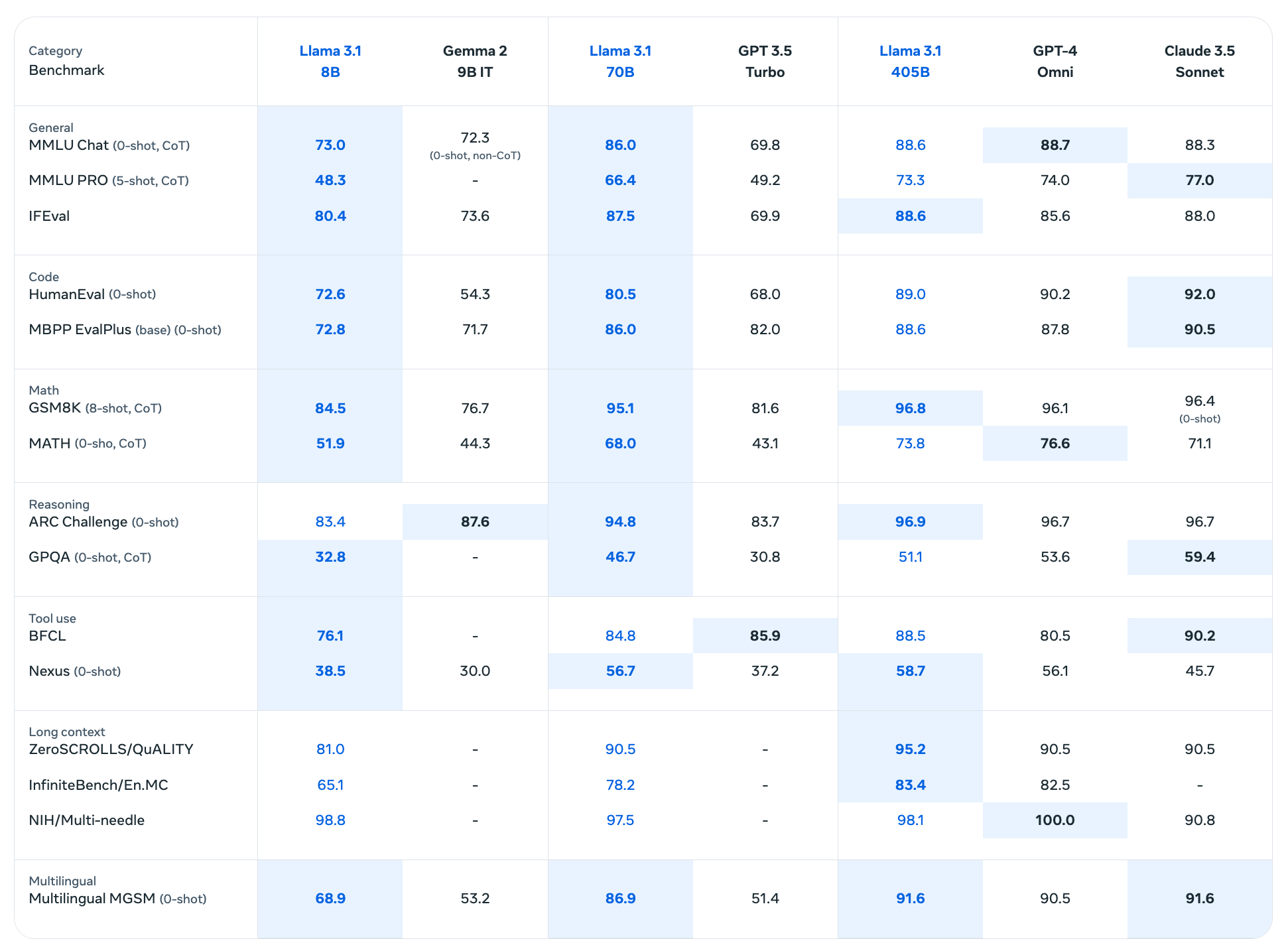
Llama 3.1 benchmarks (Meta)
Availability and Deployment:
- Open Supply: Llama 3.1 fashions can be found for obtain on Meta’s platform and Hugging Face.
- API Entry: Out there by way of numerous cloud platforms and accomplice ecosystems.
- On-Premises Deployment: Could be run regionally or on-premises with out sharing information with Meta.
Llama 3.1 Moral Concerns and Security Options
Meta has applied numerous security measures for Llama 3.1:
- Llama Guard 3: A high-performance enter and output moderation mannequin.
- Immediate Guard: A instrument for shielding LLM-powered functions from malicious prompts.
- Code Defend: Gives inference-time filtering of insecure code produced by LLMs.
- Accountable Use Information: Affords pointers for moral deployment and use of the fashions.
Llama 3.1 marks a big milestone in open-source AI growth, providing state-of-the-art efficiency whereas sustaining a concentrate on accessibility and accountable deployment. Its improved capabilities place it as a robust competitor to main closed-source fashions, remodeling the panorama of AI analysis and software growth.
Introduced in February 2024 and made obtainable for public preview in Might 2024, Google’s Gemini 1.5 Professional additionally represented a big development in AI capabilities, providing improved efficiency throughout numerous duties and modalities.
Key Capabilities:
- Multimodal Processing: Gemini 1.5 Professional can course of and generate content material throughout a number of modalities, together with textual content, photos, audio, and video.
- Prolonged Context Window: The mannequin incorporates a large context window of as much as 1 million tokens, expandable to 2 million tokens for choose customers. This enables for processing of intensive information, together with 11 hours of audio, 1 hour of video, 30,000 strains of code, or complete books.
- Superior Structure: Gemini 1.5 Professional makes use of a Combination-of-Consultants (MoE) structure, selectively activating probably the most related professional pathways inside its neural community primarily based on enter varieties.
- Improved Efficiency: Google claims that Gemini 1.5 Professional outperforms its predecessor (Gemini 1.0 Professional) in 87% of the benchmarks used to judge giant language fashions.
- Enhanced Security Options: The mannequin underwent rigorous security testing earlier than launch, with sturdy applied sciences applied to mitigate potential AI dangers.
Gemini 1.5 Professional Benchmarks and Efficiency
Gemini 1.5 Professional has demonstrated spectacular outcomes throughout numerous benchmarks:
- MMLU (Huge Multitask Language Understanding): 85.9% (5-shot setup), 91.7% (majority vote setup)
- GSM8K (Grade Faculty Math): 91.7%
- MATH (Superior mathematical reasoning): 58.5%
- HumanEval (Coding benchmark): 71.9%
- VQAv2 (Visible Query Answering): 73.2%
- MMMU (Multi-discipline reasoning): 58.5%
Google experiences that Gemini 1.5 Professional outperforms its predecessor (Gemini 1.0 Extremely) in 16 out of 19 textual content benchmarks and 18 out of 21 imaginative and prescient benchmarks.
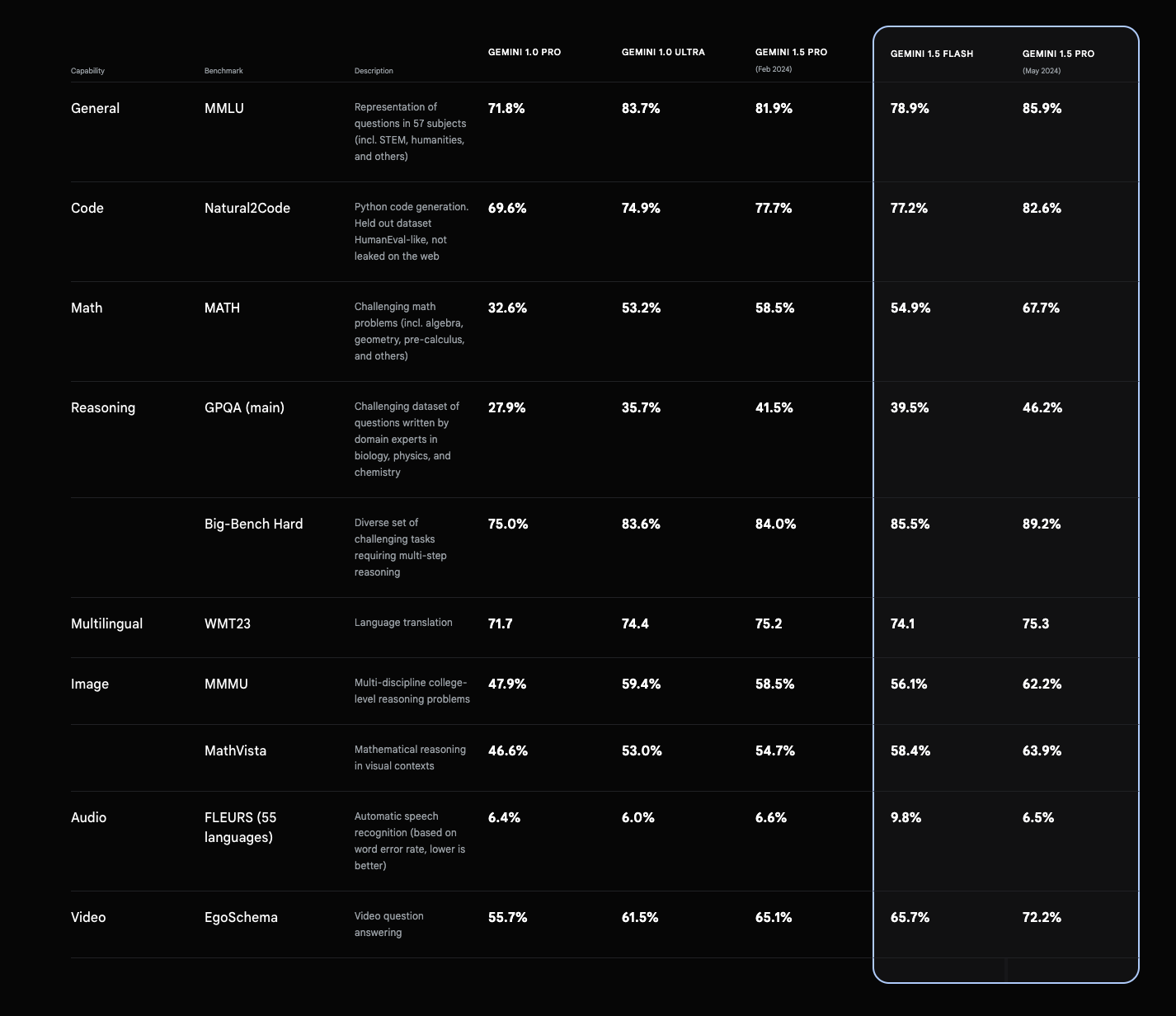
Gemini 1.5 Professional benchmarks (Google)
Key Options and Capabilities:
- Audio Comprehension: Evaluation of spoken phrases, tone, temper, and particular sounds.
- Video Evaluation: Processing of uploaded movies or movies from exterior hyperlinks.
- System Directions: Customers can information the mannequin’s response type by way of system directions.
- JSON Mode and Operate Calling: Enhanced structured output capabilities.
- Lengthy-context Studying: Capacity to be taught new abilities from info inside its prolonged context window.
Availability and Deployment:
- Google AI Studio for builders
- Vertex AI for enterprise clients
- Public API entry
Launched in August 2024 by xAI, Elon Musk’s synthetic intelligence firm, Grok-2 represents a big development over its predecessor, providing improved efficiency throughout numerous duties and introducing new capabilities.

Mannequin Variants:
- Grok-2: The complete-sized, extra highly effective mannequin
- Grok-2 mini: A smaller, extra environment friendly model
Key Capabilities:
- Enhanced Language Understanding: Improved efficiency basically information, reasoning, and language duties.
- Actual-Time Info Processing: Entry to and processing of real-time info from X (previously Twitter).
- Picture Era: Powered by Black Forest Labs’ FLUX.1 mannequin, permitting creation of photos primarily based on textual content prompts.
- Superior Reasoning: Enhanced skills in logical reasoning, problem-solving, and sophisticated process completion.
- Coding Help: Improved efficiency in coding duties.
- Multimodal Processing: Dealing with and era of content material throughout a number of modalities, together with textual content, photos, and probably audio.
Grok-2 Benchmark Efficiency
Grok-2 has proven spectacular outcomes throughout numerous benchmarks:
- GPQA (Graduate-level Skilled High quality Assurance): 56.0%
- MMLU (Huge Multitask Language Understanding): 87.5%
- MMLU-Professional: 75.5%
- MATH: 76.1%
- HumanEval (coding benchmark): 88.4%
- MMMU (Multi-Modal Multi-Activity): 66.1%
- MathVista: 69.0%
- DocVQA: 93.6%
These scores display vital enhancements over Grok-1.5 and place Grok-2 as a robust competitor to different main AI fashions.
Grok-2 benchmarks (xAI)
Availability and Deployment:
- X Platform: Grok-2 mini is offered to X Premium and Premium+ subscribers.
- Enterprise API: Each Grok-2 and Grok-2 mini can be obtainable by way of xAI’s enterprise API.
- Integration: Plans to combine Grok-2 into numerous X options, together with search and reply features.
Distinctive Options:
- “Enjoyable Mode”: A toggle for extra playful and humorous responses.
- Actual-Time Information Entry: In contrast to many different LLMs, Grok-2 can entry present info from X.
- Minimal Restrictions: Designed with fewer content material restrictions in comparison with some opponents.
Grok-2 Moral Concerns and Security Issues
Grok-2’s launch has raised considerations relating to content material moderation, misinformation dangers, and copyright points. xAI has not publicly detailed particular security measures applied in Grok-2, resulting in discussions about accountable AI growth and deployment.
Grok-2 represents a big development in AI know-how, providing improved efficiency throughout numerous duties and introducing new capabilities like picture era. Nevertheless, its launch has additionally sparked vital discussions about AI security, ethics, and accountable growth.
The Backside Line on LLMs
As we have seen, the newest developments in giant language fashions have considerably elevated the sphere of pure language processing. These LLMs, together with Claude 3, GPT-4o, Llama 3.1, Gemini 1.5 Professional, and Grok-2, symbolize the top of AI language understanding and era. Every mannequin brings distinctive strengths to the desk, from enhanced multilingual capabilities and prolonged context home windows to multimodal processing and real-time info entry. These improvements should not simply incremental enhancements however transformative leaps which might be reshaping how we method complicated language duties and AI-driven options.
The benchmark performances of those fashions underscore their distinctive capabilities, typically surpassing human-level efficiency in numerous language understanding and reasoning duties. This progress is a testomony to the facility of superior coaching methods, refined neural architectures, and huge quantities of numerous coaching information. As these LLMs proceed to evolve, we are able to count on much more groundbreaking functions in fields reminiscent of content material creation, code era, information evaluation, and automatic reasoning.
Nevertheless, as these language fashions grow to be more and more highly effective and accessible, it is essential to handle the moral concerns and potential dangers related to their deployment. Accountable AI growth, sturdy security measures, and clear practices can be key to harnessing the complete potential of those LLMs whereas mitigating potential hurt. As we glance to the longer term, the continued refinement and accountable implementation of those giant language fashions will play a pivotal function in shaping the panorama of synthetic intelligence and its impression on society.

