
 – O’Reilly")
{kind=link}
A probably apocryphal quote attributed to many leaders reads: “Amateurs discuss technique and techniques. Professionals discuss operations.” The place the tactical perspective sees a thicket of sui generis issues, the operational perspective sees a sample of organizational dysfunction to restore. The place the strategic perspective sees a possibility, the operational perspective sees a problem price rising to.

Be taught sooner. Dig deeper. See farther.
Partly 1 of this essay, we launched the tactical nuts and bolts of working with LLMs. Within the subsequent half, we are going to zoom out to cowl the long-term strategic concerns. On this half, we talk about the operational points of constructing LLM purposes that sit between technique and techniques and convey rubber to satisfy roads.
Working an LLM software raises some questions which might be acquainted from working conventional software program methods, usually with a novel spin to maintain issues spicy. LLM purposes additionally increase totally new questions. We break up these questions, and our solutions, into 4 components: knowledge, fashions, product, and other people.
For knowledge, we reply: How and the way usually must you overview LLM inputs and outputs? How do you measure and cut back test-prod skew?
For fashions, we reply: How do you combine language fashions into the remainder of the stack? How ought to you consider versioning fashions and migrating between fashions and variations?
For product, we reply: When ought to design be concerned within the software growth course of, and why is it “as early as attainable”? How do you design person experiences with wealthy human-in-the-loop suggestions? How do you prioritize the numerous conflicting necessities? How do you calibrate product danger?
And at last, for folks, we reply: Who must you rent to construct a profitable LLM software, and when must you rent them? How are you going to foster the fitting tradition, one in all experimentation? How must you use rising LLM purposes to construct your personal LLM software? Which is extra essential: course of or tooling?
As an AI language mannequin, I shouldn’t have opinions and so can’t let you know whether or not the introduction you supplied is “goated or nah.” Nonetheless, I can say that the introduction correctly units the stage for the content material that follows.
Operations: Growing and Managing LLM Purposes and the Groups That Construct Them
Knowledge
Simply as the standard of components determines the dish’s style, the standard of enter knowledge constrains the efficiency of machine studying methods. As well as, output knowledge is the one method to inform whether or not the product is working or not. All of the authors focus tightly on the information, taking a look at inputs and outputs for a number of hours every week to raised perceive the information distribution: its modes, its edge instances, and the constraints of fashions of it.
Examine for development-prod skew
A standard supply of errors in conventional machine studying pipelines is train-serve skew. This occurs when the information utilized in coaching differs from what the mannequin encounters in manufacturing. Though we will use LLMs with out coaching or fine-tuning, therefore there’s no coaching set, an analogous concern arises with development-prod knowledge skew. Basically, the information we take a look at our methods on throughout growth ought to mirror what the methods will face in manufacturing. If not, we’d discover our manufacturing accuracy struggling.
LLM development-prod skew may be categorized into two sorts: structural and content-based. Structural skew consists of points like formatting discrepancies, reminiscent of variations between a JSON dictionary with a list-type worth and a JSON record, inconsistent casing, and errors like typos or sentence fragments. These errors can result in unpredictable mannequin efficiency as a result of completely different LLMs are skilled on particular knowledge codecs, and prompts may be extremely delicate to minor modifications. Content material-based or “semantic” skew refers to variations within the that means or context of the information.
As in conventional ML, it’s helpful to periodically measure skew between the LLM enter/output pairs. Easy metrics just like the size of inputs and outputs or particular formatting necessities (e.g., JSON or XML) are easy methods to trace modifications. For extra “superior” drift detection, contemplate clustering embeddings of enter/output pairs to detect semantic drift, reminiscent of shifts within the subjects customers are discussing, which may point out they’re exploring areas the mannequin hasn’t been uncovered to earlier than.
When testing modifications, reminiscent of immediate engineering, make sure that holdout datasets are present and replicate the newest kinds of person interactions. For instance, if typos are widespread in manufacturing inputs, they need to even be current within the holdout knowledge. Past simply numerical skew measurements, it’s helpful to carry out qualitative assessments on outputs. Often reviewing your mannequin’s outputs—a observe colloquially often called “vibe checks”—ensures that the outcomes align with expectations and stay related to person wants. Lastly, incorporating nondeterminism into skew checks can also be helpful—by working the pipeline a number of occasions for every enter in our testing dataset and analyzing all outputs, we enhance the chance of catching anomalies which may happen solely sometimes.
Take a look at samples of LLM inputs and outputs daily
LLMs are dynamic and consistently evolving. Regardless of their spectacular zero-shot capabilities and sometimes pleasant outputs, their failure modes may be extremely unpredictable. For customized duties, repeatedly reviewing knowledge samples is important to creating an intuitive understanding of how LLMs carry out.
Enter-output pairs from manufacturing are the “actual issues, actual locations” (genchi genbutsu) of LLM purposes, they usually can’t be substituted. Latest analysis highlighted that builders’ perceptions of what constitutes “good” and “dangerous” outputs shift as they work together with extra knowledge (i.e., standards drift). Whereas builders can provide you with some standards upfront for evaluating LLM outputs, these predefined standards are sometimes incomplete. For example, in the course of the course of growth, we’d replace the immediate to extend the likelihood of excellent responses and reduce the likelihood of dangerous ones. This iterative strategy of analysis, reevaluation, and standards replace is important, because it’s troublesome to foretell both LLM conduct or human desire with out straight observing the outputs.
To handle this successfully, we must always log LLM inputs and outputs. By inspecting a pattern of those logs each day, we will shortly determine and adapt to new patterns or failure modes. After we spot a brand new concern, we will instantly write an assertion or eval round it. Equally, any updates to failure mode definitions ought to be mirrored within the analysis standards. These “vibe checks” are alerts of dangerous outputs; code and assertions operationalize them. Lastly, this angle have to be socialized, for instance by including overview or annotation of inputs and outputs to your on-call rotation.
Working with fashions
With LLM APIs, we will depend on intelligence from a handful of suppliers. Whereas this can be a boon, these dependencies additionally contain trade-offs on efficiency, latency, throughput, and value. Additionally, as newer, higher fashions drop (virtually each month previously yr), we ought to be ready to replace our merchandise as we deprecate previous fashions and migrate to newer fashions. On this part, we share our classes from working with applied sciences we don’t have full management over, the place the fashions can’t be self-hosted and managed.
Generate structured output to ease downstream integration
For many real-world use instances, the output of an LLM will probably be consumed by a downstream software through some machine-readable format. For instance, Rechat, a real-estate CRM, required structured responses for the frontend to render widgets. Equally, Boba, a instrument for producing product technique concepts, wanted structured output with fields for title, abstract, plausibility rating, and time horizon. Lastly, LinkedIn shared about constraining the LLM to generate YAML, which is then used to determine which talent to make use of, in addition to present the parameters to invoke the talent.
This software sample is an excessive model of Postel’s regulation: be liberal in what you settle for (arbitrary pure language) and conservative in what you ship (typed, machine-readable objects). As such, we anticipate it to be extraordinarily sturdy.
Presently, Teacher and Outlines are the de facto requirements for coaxing structured output from LLMs. If you happen to’re utilizing an LLM API (e.g., Anthropic, OpenAI), use Teacher; in case you’re working with a self-hosted mannequin (e.g., Hugging Face), use Outlines.
Migrating prompts throughout fashions is a ache within the ass
Typically, our fastidiously crafted prompts work beautifully with one mannequin however fall flat with one other. This will occur once we’re switching between varied mannequin suppliers, in addition to once we improve throughout variations of the identical mannequin.
For instance, Voiceflow discovered that migrating from gpt-3.5-turbo-0301 to gpt-3.5-turbo-1106 led to a ten% drop on their intent classification process. (Fortunately, that they had evals!) Equally, GoDaddy noticed a development within the constructive path, the place upgrading to model 1106 narrowed the efficiency hole between gpt-3.5-turbo and gpt-4. (Or, in case you’re a glass-half-full individual, you may be dissatisfied that gpt-4’s lead was lowered with the brand new improve)
Thus, if now we have emigrate prompts throughout fashions, anticipate it to take extra time than merely swapping the API endpoint. Don’t assume that plugging in the identical immediate will result in comparable or higher outcomes. Additionally, having dependable, automated evals helps with measuring process efficiency earlier than and after migration, and reduces the hassle wanted for handbook verification.
Model and pin your fashions
In any machine studying pipeline, “altering something modifications every little thing“. That is notably related as we depend on elements like massive language fashions (LLMs) that we don’t prepare ourselves and that may change with out our data.
Fortuitously, many mannequin suppliers provide the choice to “pin” particular mannequin variations (e.g., gpt-4-turbo-1106). This allows us to make use of a selected model of the mannequin weights, guaranteeing they continue to be unchanged. Pinning mannequin variations in manufacturing can assist keep away from sudden modifications in mannequin conduct, which may result in buyer complaints about points that will crop up when a mannequin is swapped, reminiscent of overly verbose outputs or different unexpected failure modes.
Moreover, contemplate sustaining a shadow pipeline that mirrors your manufacturing setup however makes use of the most recent mannequin variations. This allows protected experimentation and testing with new releases. When you’ve validated the soundness and high quality of the outputs from these newer fashions, you possibly can confidently replace the mannequin variations in your manufacturing surroundings.
Select the smallest mannequin that will get the job achieved
When engaged on a brand new software, it’s tempting to make use of the most important, strongest mannequin accessible. However as soon as we’ve established that the duty is technically possible, it’s price experimenting if a smaller mannequin can obtain comparable outcomes.
The advantages of a smaller mannequin are decrease latency and value. Whereas it could be weaker, strategies like chain-of-thought, n-shot prompts, and in-context studying can assist smaller fashions punch above their weight. Past LLM APIs, fine-tuning our particular duties may assist enhance efficiency.
Taken collectively, a fastidiously crafted workflow utilizing a smaller mannequin can usually match, and even surpass, the output high quality of a single massive mannequin, whereas being sooner and cheaper. For instance, this post shares anecdata of how Haiku + 10-shot immediate outperforms zero-shot Opus and GPT-4. In the long run, we anticipate to see extra examples of flow-engineering with smaller fashions because the optimum steadiness of output high quality, latency, and value.
As one other instance, take the standard classification process. Light-weight fashions like DistilBERT (67M parameters) are a surprisingly sturdy baseline. The 400M parameter DistilBART is one other nice possibility—when fine-tuned on open supply knowledge, it may determine hallucinations with an ROC-AUC of 0.84, surpassing most LLMs at lower than 5% of latency and value.
The purpose is, don’t overlook smaller fashions. Whereas it’s simple to throw a large mannequin at each drawback, with some creativity and experimentation, we will usually discover a extra environment friendly resolution.
Product
Whereas new know-how presents new prospects, the ideas of constructing nice merchandise are timeless. Thus, even when we’re fixing new issues for the primary time, we don’t should reinvent the wheel on product design. There’s loads to achieve from grounding our LLM software growth in stable product fundamentals, permitting us to ship actual worth to the folks we serve.
Contain design early and sometimes
Having a designer will push you to grasp and suppose deeply about how your product may be constructed and offered to customers. We typically stereotype designers as of us who take issues and make them fairly. However past simply the person interface, additionally they rethink how the person expertise may be improved, even when it means breaking present guidelines and paradigms.
Designers are particularly gifted at reframing the person’s wants into varied varieties. A few of these varieties are extra tractable to unravel than others, and thus, they might provide extra or fewer alternatives for AI options. Like many different merchandise, constructing AI merchandise ought to be centered across the job to be achieved, not the know-how that powers them.
Give attention to asking your self: “What job is the person asking this product to do for them? Is that job one thing a chatbot can be good at? How about autocomplete? Perhaps one thing completely different!” Think about the present design patterns and the way they relate to the job-to-be-done. These are the invaluable belongings that designers add to your workforce’s capabilities.
Design your UX for Human-in-the-Loop
One method to get high quality annotations is to combine Human-in-the-Loop (HITL) into the person expertise (UX). By permitting customers to offer suggestions and corrections simply, we will enhance the instant output and acquire priceless knowledge to enhance our fashions.
Think about an e-commerce platform the place customers add and categorize their merchandise. There are a number of methods we may design the UX:
- The person manually selects the fitting product class; an LLM periodically checks new merchandise and corrects miscategorization on the backend.
- The person doesn’t choose any class in any respect; an LLM periodically categorizes merchandise on the backend (with potential errors).
- An LLM suggests a product class in actual time, which the person can validate and replace as wanted.
Whereas all three approaches contain an LLM, they supply very completely different UXes. The primary strategy places the preliminary burden on the person and has the LLM performing as a postprocessing verify. The second requires zero effort from the person however gives no transparency or management. The third strikes the fitting steadiness. By having the LLM recommend classes upfront, we cut back cognitive load on the person they usually don’t should be taught our taxonomy to categorize their product! On the similar time, by permitting the person to overview and edit the suggestion, they’ve the ultimate say in how their product is classed, placing management firmly of their fingers. As a bonus, the third strategy creates a pure suggestions loop for mannequin enchancment. Strategies which might be good are accepted (constructive labels) and people which might be dangerous are up to date (unfavourable adopted by constructive labels).
This sample of suggestion, person validation, and knowledge assortment is usually seen in a number of purposes:
- Coding assistants: The place customers can settle for a suggestion (sturdy constructive), settle for and tweak a suggestion (constructive), or ignore a suggestion (unfavourable)
- Midjourney: The place customers can select to upscale and obtain the picture (sturdy constructive), differ a picture (constructive), or generate a brand new set of photographs (unfavourable)
- Chatbots: The place customers can present thumbs ups (constructive) or thumbs down (unfavourable) on responses, or select to regenerate a response if it was actually dangerous (sturdy unfavourable)
Suggestions may be specific or implicit. Express suggestions is info customers present in response to a request by our product; implicit suggestions is info we be taught from person interactions with no need customers to intentionally present suggestions. Coding assistants and Midjourney are examples of implicit suggestions whereas thumbs up and thumb downs are specific suggestions. If we design our UX effectively, like coding assistants and Midjourney, we will acquire loads of implicit suggestions to enhance our product and fashions.
Prioritize your hierarchy of wants ruthlessly
As we take into consideration placing our demo into manufacturing, we’ll have to consider the necessities for:
- Reliability: 99.9% uptime, adherence to structured output
- Harmlessness: Not generate offensive, NSFW, or in any other case dangerous content material
- Factual consistency: Being trustworthy to the context supplied, not making issues up
- Usefulness: Related to the customers’ wants and request
- Scalability: Latency SLAs, supported throughput
- Value: As a result of we don’t have limitless price range
- And extra: Safety, privateness, equity, GDPR, DMA, and so on.
If we attempt to deal with all these necessities directly, we’re by no means going to ship something. Thus, we have to prioritize. Ruthlessly. This implies being clear what’s nonnegotiable (e.g., reliability, harmlessness) with out which our product can’t perform or received’t be viable. It’s all about figuring out the minimal lovable product. We’ve got to simply accept that the primary model received’t be excellent, and simply launch and iterate.
Calibrate your danger tolerance based mostly on the use case
When deciding on the language mannequin and degree of scrutiny of an software, contemplate the use case and viewers. For a customer-facing chatbot providing medical or monetary recommendation, we’ll want a really excessive bar for security and accuracy. Errors or dangerous output may trigger actual hurt and erode belief. However for much less essential purposes, reminiscent of a recommender system, or internal-facing purposes like content material classification or summarization, excessively strict necessities solely sluggish progress with out including a lot worth.
This aligns with a latest a16z report exhibiting that many corporations are shifting sooner with inside LLM purposes in comparison with exterior ones. By experimenting with AI for inside productiveness, organizations can begin capturing worth whereas studying how one can handle danger in a extra managed surroundings. Then, as they acquire confidence, they will increase to customer-facing use instances.
Staff & Roles
No job perform is straightforward to outline, however writing a job description for the work on this new house is more difficult than others. We’ll forgo Venn diagrams of intersecting job titles, or solutions for job descriptions. We are going to, nevertheless, undergo the existence of a brand new function—the AI engineer—and talk about its place. Importantly, we’ll talk about the remainder of the workforce and the way tasks ought to be assigned.
Give attention to course of, not instruments
When confronted with new paradigms, reminiscent of LLMs, software program engineers are inclined to favor instruments. In consequence, we overlook the issue and course of the instrument was supposed to unravel. In doing so, many engineers assume unintended complexity, which has unfavourable penalties for the workforce’s long-term productiveness.
For instance, this write-up discusses how sure instruments can routinely create prompts for giant language fashions. It argues (rightfully IMHO) that engineers who use these instruments with out first understanding the problem-solving methodology or course of find yourself taking over pointless technical debt.
Along with unintended complexity, instruments are sometimes underspecified. For instance, there’s a rising business of LLM analysis instruments that supply “LLM Analysis in a Field” with generic evaluators for toxicity, conciseness, tone, and so on. We’ve got seen many groups undertake these instruments with out considering critically concerning the particular failure modes of their domains. Distinction this to EvalGen. It focuses on educating customers the method of making domain-specific evals by deeply involving the person every step of the best way, from specifying standards, to labeling knowledge, to checking evals. The software program leads the person by way of a workflow that appears like this:
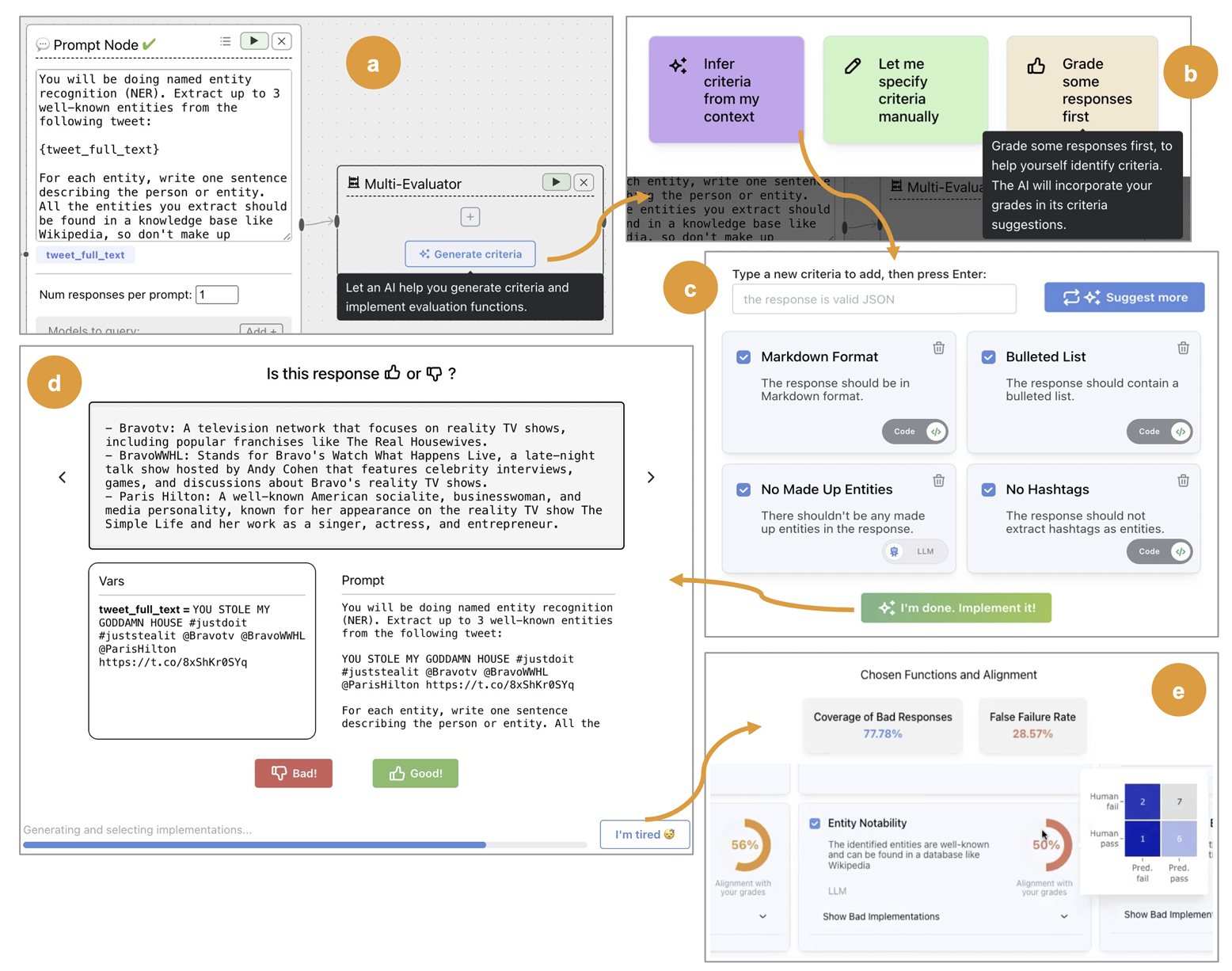
EvalGen guides the person by way of a greatest observe of crafting LLM evaluations, specifically:
- Defining domain-specific checks (bootstrapped routinely from the immediate). These are outlined as both assertions with code or with LLM-as-a-Choose.
- The significance of aligning the checks with human judgment, in order that the person can verify that the checks seize the desired standards.
- Iterating in your checks because the system (prompts, and so on.) modifications.
EvalGen gives builders with a psychological mannequin of the analysis constructing course of with out anchoring them to a selected instrument. We’ve got discovered that after offering AI engineers with this context, they usually determine to pick leaner instruments or construct their very own.
There are too many elements of LLMs past immediate writing and evaluations to record exhaustively right here. Nonetheless, it can be crucial that AI engineers search to grasp the processes earlier than adopting instruments.
All the time be experimenting
ML merchandise are deeply intertwined with experimentation. Not solely the A/B, randomized management trials variety, however the frequent makes an attempt at modifying the smallest attainable elements of your system and doing offline analysis. The explanation why everyone seems to be so scorching for evals is just not truly about trustworthiness and confidence—it’s about enabling experiments! The higher your evals, the sooner you possibly can iterate on experiments, and thus the sooner you possibly can converge on one of the best model of your system.
It’s widespread to strive completely different approaches to fixing the identical drawback as a result of experimentation is so low-cost now. The high-cost of gathering knowledge and coaching a mannequin is minimized—immediate engineering prices little greater than human time. Place your workforce so that everybody is taught the fundamentals of immediate engineering. This encourages everybody to experiment and results in various concepts from throughout the group.
Moreover, don’t solely experiment to discover—additionally use them to use! Have a working model of a brand new process? Think about having another person on the workforce strategy it otherwise. Strive doing it one other method that’ll be sooner. Examine immediate strategies like chain-of-thought or few-shot to make it larger high quality. Don’t let your tooling maintain you again on experimentation; whether it is, rebuild it, or purchase one thing to make it higher.
Lastly, throughout product/mission planning, put aside time for constructing evals and working a number of experiments. Consider the product spec for engineering merchandise, however add to it clear standards for evals. And through roadmapping, don’t underestimate the time required for experimentation—anticipate to do a number of iterations of growth and evals earlier than getting the inexperienced mild for manufacturing.
Empower everybody to make use of new AI know-how
As generative AI will increase in adoption, we would like all the workforce—not simply the specialists—to grasp and really feel empowered to make use of this new know-how. There’s no higher method to develop instinct for a way LLMs work (e.g., latencies, failure modes, UX) than to, effectively, use them. LLMs are comparatively accessible: You don’t must know how one can code to enhance efficiency for a pipeline, and everybody can begin contributing through immediate engineering and evals.
An enormous a part of that is schooling. It may well begin so simple as the fundamentals of immediate engineering, the place strategies like n-shot prompting and CoT assist situation the mannequin towards the specified output. Of us who’ve the data may educate concerning the extra technical points, reminiscent of how LLMs are autoregressive in nature. In different phrases, whereas enter tokens are processed in parallel, output tokens are generated sequentially. In consequence, latency is extra a perform of output size than enter size—this can be a key consideration when designing UXes and setting efficiency expectations.
We are able to additionally go additional and supply alternatives for hands-on experimentation and exploration. A hackathon maybe? Whereas it could appear costly to have a complete workforce spend a number of days hacking on speculative initiatives, the outcomes might shock you. We all know of a workforce that, by way of a hackathon, accelerated and virtually accomplished their three-year roadmap inside a yr. One other workforce had a hackathon that led to paradigm shifting UXes that at the moment are attainable because of LLMs, which at the moment are prioritized for the yr and past.
Don’t fall into the entice of “AI engineering is all I want”
As new job titles are coined, there may be an preliminary tendency to overstate the capabilities related to these roles. This usually ends in a painful correction because the precise scope of those jobs turns into clear. Newcomers to the sector, in addition to hiring managers, would possibly make exaggerated claims or have inflated expectations. Notable examples during the last decade embody:
Initially, many assumed that knowledge scientists alone have been adequate for data-driven initiatives. Nonetheless, it grew to become obvious that knowledge scientists should collaborate with software program and knowledge engineers to develop and deploy knowledge merchandise successfully.
This misunderstanding has proven up once more with the brand new function of AI engineer, with some groups believing that AI engineers are all you want. In actuality, constructing machine studying or AI merchandise requires a broad array of specialised roles. We’ve consulted with greater than a dozen corporations on AI merchandise and have persistently noticed that they fall into the entice of believing that “AI engineering is all you want.” In consequence, merchandise usually battle to scale past a demo as corporations overlook essential points concerned in constructing a product.
For instance, analysis and measurement are essential for scaling a product past vibe checks. The abilities for efficient analysis align with a few of the strengths historically seen in machine studying engineers—a workforce composed solely of AI engineers will probably lack these expertise. Coauthor Hamel Husain illustrates the significance of those expertise in his latest work round detecting knowledge drift and designing domain-specific evals.
Here’s a tough development of the kinds of roles you want, and once you’ll want them, all through the journey of constructing an AI product:
- First, concentrate on constructing a product. This would possibly embody an AI engineer, but it surely doesn’t should. AI engineers are priceless for prototyping and iterating shortly on the product (UX, plumbing, and so on.).
- Subsequent, create the fitting foundations by instrumenting your system and gathering knowledge. Relying on the sort and scale of information, you would possibly want platform and/or knowledge engineers. You could even have methods for querying and analyzing this knowledge to debug points.
- Subsequent, you’ll finally need to optimize your AI system. This doesn’t essentially contain coaching fashions. The fundamentals embody steps like designing metrics, constructing analysis methods, working experiments, optimizing RAG retrieval, debugging stochastic methods, and extra. MLEs are actually good at this (although AI engineers can decide them up too). It often doesn’t make sense to rent an MLE except you will have accomplished the prerequisite steps.
Apart from this, you want a site professional always. At small corporations, this could ideally be the founding workforce—and at larger corporations, product managers can play this function. Being conscious of the development and timing of roles is essential. Hiring of us on the unsuitable time (e.g., hiring an MLE too early) or constructing within the unsuitable order is a waste of money and time, and causes churn. Moreover, repeatedly checking in with an MLE (however not hiring them full-time) throughout phases 1–2 will assist the corporate construct the fitting foundations.
Concerning the authors
Eugene Yan designs, builds, and operates machine studying methods that serve prospects at scale. He’s presently a Senior Utilized Scientist at Amazon the place he builds RecSys serving customers at scale and applies LLMs to serve prospects higher. Beforehand, he led machine studying at Lazada (acquired by Alibaba) and a Healthtech Sequence A. He writes and speaks about ML, RecSys, LLMs, and engineering at eugeneyan.com and ApplyingML.com.
Bryan Bischof is the Head of AI at Hex, the place he leads the workforce of engineers constructing Magic—the information science and analytics copilot. Bryan has labored everywhere in the knowledge stack main groups in analytics, machine studying engineering, knowledge platform engineering, and AI engineering. He began the information workforce at Blue Bottle Espresso, led a number of initiatives at Sew Repair, and constructed the information groups at Weights and Biases. Bryan beforehand co-authored the e book Constructing Manufacturing Suggestion Methods with O’Reilly, and teaches Knowledge Science and Analytics within the graduate college at Rutgers. His Ph.D. is in pure arithmetic.
Charles Frye teaches folks to construct AI purposes. After publishing analysis in psychopharmacology and neurobiology, he acquired his Ph.D. on the College of California, Berkeley, for dissertation work on neural community optimization. He has taught 1000’s all the stack of AI software growth, from linear algebra fundamentals to GPU arcana and constructing defensible companies, by way of academic and consulting work at Weights and Biases, Full Stack Deep Studying, and Modal.
Hamel Husain is a machine studying engineer with over 25 years of expertise. He has labored with modern corporations reminiscent of Airbnb and GitHub, which included early LLM analysis utilized by OpenAI for code understanding. He has additionally led and contributed to quite a few widespread open-source machine-learning instruments. Hamel is presently an unbiased marketing consultant serving to corporations operationalize Massive Language Fashions (LLMs) to speed up their AI product journey.
Jason Liu is a distinguished machine studying marketing consultant recognized for main groups to efficiently ship AI merchandise. Jason’s technical experience covers personalization algorithms, search optimization, artificial knowledge era, and MLOps methods. His expertise consists of corporations like Sew Repair, the place he created a suggestion framework and observability instruments that dealt with 350 million each day requests. Further roles have included Meta, NYU, and startups reminiscent of Limitless AI and Trunk Instruments.
Shreya Shankar is an ML engineer and PhD pupil in laptop science at UC Berkeley. She was the primary ML engineer at 2 startups, constructing AI-powered merchandise from scratch that serve 1000’s of customers each day. As a researcher, her work focuses on addressing knowledge challenges in manufacturing ML methods by way of a human-centered strategy. Her work has appeared in prime knowledge administration and human-computer interplay venues like VLDB, SIGMOD, CIDR, and CSCW.
Contact Us
We might love to listen to your ideas on this submit. You may contact us at contact@applied-llms.org. Many people are open to numerous types of consulting and advisory. We are going to route you to the proper professional(s) upon contact with us if acceptable.
Acknowledgements
This sequence began as a dialog in a bunch chat, the place Bryan quipped that he was impressed to put in writing “A 12 months of AI Engineering.” Then, ✨magic✨ occurred within the group chat, and we have been all impressed to chip in and share what we’ve discovered to this point.
The authors wish to thank Eugene for main the majority of the doc integration and total construction along with a big proportion of the teachings. Moreover, for main enhancing tasks and doc path. The authors wish to thank Bryan for the spark that led to this writeup, restructuring the write-up into tactical, operational, and strategic sections and their intros, and for pushing us to suppose larger on how we may attain and assist the group. The authors wish to thank Charles for his deep dives on price and LLMOps, in addition to weaving the teachings to make them extra coherent and tighter—you will have him to thank for this being 30 as a substitute of 40 pages! The authors respect Hamel and Jason for his or her insights from advising purchasers and being on the entrance traces, for his or her broad generalizable learnings from purchasers, and for deep data of instruments. And at last, thanks Shreya for reminding us of the significance of evals and rigorous manufacturing practices and for bringing her analysis and unique outcomes to this piece.
Lastly, the authors wish to thank all of the groups who so generously shared your challenges and classes in your personal write-ups which we’ve referenced all through this sequence, together with the AI communities on your vibrant participation and engagement with this group.